一、流程控制语句
1、条件判断式
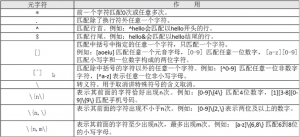
1)按照文件类型进行判断

两种判断格式
[root@localhost ~]# test -e /root/install.log [root@localhost ~]# [ -e /root/install.log ]
简单的判断式
[root@localhost ~]# [ -d /root ] && echo "yest" || echo "no" #第一个判断命令如果正确执行,则打印"yes",否则打印"no"
2)按照文件权限进行判断
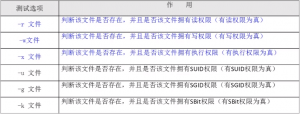
[root@localhost ~]# [ -w student.txt] && echo "yes" || echo "no" #判断文件是拥有写权限的
3)两个文件之间进行比较

[root@localhost ~]# ln /root/student.txt /tmp/stu.txt #创建硬链接 [root@localhost ~]# [ /root/student.txt -ef /tmp/stu.txt] && echo "yes" || echo "no" #判断两个文件是否为同一个文件
4)两个整数之间的比较

[root@localhost ~]# [ 23 -ge 22 ] && echo "yes" || echo "no" #判断23是否大于等于22 [root@localhost ~]# [ 23 -le 22 ] && echo "yes" || echo "no" #判断23是否小于等于22
5)字符串的判断
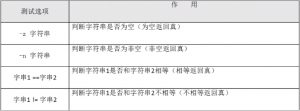
[root@localhost ~]# name=fengj @给name变量赋值 [root@localhost ~]# [ -z "$name" ] && echo "yes" || echo "no" #判断name变量是否为空 [root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和变量bb赋值 [root@localhost ~]# [ "$aa" == "bb" ] && echo "yes" || echo "no" #判断两个变量的值是否相等
6)多重条件判断

[root@localhost ~]# aa=11 [root@localhost ~]# [ -n "$aa" -a "$aa" -gt 23 ] && echo "yes" || echo "no" #判断变量aa是否有值,同时判断变量aa的是否大于23 #因为变量aa的值不大于23,所以虽然第一个判断值为真,返回的结果也是假
2、单分支if语句
单分支if条件语句
if [ 条件判断式 ];then 程序 fi #或者 if [ 条件判断式 ] then 程序 fi
单分支条件语句需要注意几个点
#if语句使用fi结尾,和一般语言使用大括号结尾不同
#[ 条件判断式 ]就是使用test命令判断,所以中括号和条件判断式之间必须有空格
#then后面跟符合条件之后执行的程序,可以放在[]之后,用”;”分割。也可以换行写入,就不需要”;”了
例子1:判断登陆的用户是否为root
#!/bin/bash test=$(env | grep "USER" | cut -d "=" -f 2) if [ "$test" == root] then echo "Current user is root." fi
例子2:判断分区使用率
#!/bin/bash
#统计根分区使用率
#把根分区使用率作为变量值赋予变量rate
rate=$(df -h | grep "/dev/sda3" | awk '{print $5}' | cut -d "%" -f 1)
if [ $rate -ge 80 ]
then
echo "Warning! /dev/sda3 is full!!"
fi
3、双分支if语句
双分支if条件语句
if [ 条件判断式 ]
then
条件成立时,执行的程序
else
条件不成立时,执行的另一个程序
fi
例子1:判断输入的是否是一个目录
#!/bin/bash
#判断输入的文件是否是一个目录
read -t 30 -p "Please input a directory: " dir
if [ -d $dir ]
then
echo "yes"
else
echo "no"
fi
例子2:判断apache是否启动
#!/bin/bash
#截取httpd进程,并把结果赋予变量test
test=$(ps aux | grep httpd | grep -v grep)
if [ -n "$test" ]
#如果test的值不为空,则执行then中命令
then
echo "$(date) httpd is ok!" >> /tmp/autostart-acc.log
else
/etc/rc.d/init.d/httpd start &> /dev/null
echo "$(date) restart httpd !!" >> /tmp/autostart-err.log
fi
4、多分支if语句
多分支if条件语句
if [ 条件判断式1 ]
then
当条件判断式1成立时,执行程序1
elif [ 条件判断式2 ]
then
当条件判断式2成立时,执行程序2
...省略更多条件
else
当所有条件都不成立时,最后执行此程序
fi
例子
#!/bin/bash
#字符界面加减乘除计算器
read -t 30 -p "Please input num1: " num1
read -t 30 -p "Please input num2: " num2
#通过read命令接收要计算的数值,并赋予变量num1和num2
read -t 30 -p "Please input a operator: " ope
if [ -n "$num1" -a -n "$num2" -a -n "$ope" ]
#第一层判断,用来判断num1,num2和ope中都有值
then
test1=$(echo $num1 | sed 's/[0-9]//g')
test2=$(echo $num2 | sed 's/[0-9]//g')
#定义变量test1和test2的值为$(命令)的结果
#后续命令作用是,把变量test1的值替换为空。如果能替换为空,证明num1的值为数字
#如果不能替换为空,证明num1的值为非数字。我们使用这种方法判断变量num1的值为数字
#用同样的方法测试test2变量
if [ -z "$test1" -a -z "$test2" ]
#第二层判断,用来判断num1和num2为数值
#如果变量test1和test2的值为空,则证明num1和num2是数字
then
#如果test1和test2是数字,则执行以下命令
if [ "$ope" == '+' }
#第三层判断用来确认运算符
#测试变量$ope中是什么运算符
then
sum=$(( $num1 + $num2))
#如果是加号则执行加法运算
elif [ "$ope" == '-' ]
then
sum=$(($num1 - $num2))
#如果是减号,则执行减法运算
elif [ "$ope" == '*' ]
then
sum=$(( $num1 * $num2))
#如果是乘号,则执行乘法运算
elif [ "$ope" == '/' ]
then
sum=$(( $num1 / $num2))
#如果除号,则执行除法运算
elif [ "$ope" == '%' ]
then
sum=$(( $num1 % $num2))
#如果是取模,则执行取模运算
else
echo "Please enter a valid symbol"
#如果运算符不匹配,提示输入有效的符号
exit 10
#并退出程序,返回错误代码10
fi
elif
#如果test1和test2不为空,说明num1和num2不是数字
echo "Please enter a valid value"
#则提示输入有效的数值
exit 11
#并退出程序,返回错误代码11
fi
elif
echo "qing shuru neirong"
exit 12
fi
echo " $num1 $ope $num2 : $num"
#输出数值运算的结果
例子:从1加到100
#!/bin/bash
#从1加到100
s=0
for(( i=1;i<=100;i=i+1 ))
do
s=$(( $s+$i))
done
echo "The sum of 1+2+...+100 is: $s"
例子:批量添加指定数量的用户
#!/bin/bash
#批量添加指定数量的用户
read -p "Please input user name: " -t 30 name
read -p "Please input the number of users: " -t 30 num
read -p "Please input the password of users: " -t 30 pass
if [ ! -z "$name" -a ! -z "$num" -a ! -z "$pass"]
then
y=$(echo $num | sed 's/[0-9]//g')
if [ -z "$y" ]
then
for(( i=1;i<=$num;i=i+1 )) do /usr/sbin/useradd $name$i &>/dev/null
echo $pass | /usr/bin/passwd --stdin $name$i &>/dev/null
done
fi
fi
5、case语句
多分支case条件语句
#case语句和if..elif..else语句一样都是多分支条件语句,不过和if多分支条件语句不同的是,case语句只能判断一种条件关系,而if语句可以判断多种条件关系。
case $变量名 in
"值1")
如果变量的值等于值1,则执行程序1
;;
"值2")
如果变量的值等于值2,则执行程序2
;;
...省略其他分支
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
6、for循环
语法一:
for 变量 in 值1 值2 值3 ...
do
程序
done
例子:批量解压脚本
#!/bin/bash
#批量解压缩脚本
cd /root/test
ls *.tar.gz > /tmp/ls.log
for i in $(cat ls.log)
do
tar -zxf $i &>/dev/null
done
rm -rf /tmp/ls.log
语法二
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
7、while循环和until循环
1)while循环
while循环是不定循环,也称作条件循环。只要条件判断式成立,循环就会一直继续,直到条件判断式不成立,循环才停止。这就和for的固定循环不太一样了。
while [ 条件判断式 ]
do
程序
done
2)until循环
# until循环,和while循环相反,until循环时只要条件判断式不成立则进行循环,并执行循环程序。一旦循环条件成立,则终止循环。
until [ 条件判断式 ]
do
程序
done