1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like ‘%abc%’
若要提高效率,可以考虑全文检索。
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=’abc’–name以abc开头的id
select id from t where datediff(day,createdate,’2005-11-30′)=0–‘2005-11-30’生成的id
应改为:
select id from t where name like ‘abc%’
select id from t where createdate>=’2005-11-30′ and createdate<‘2005-12-1’
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)
13.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21.避免频繁创建和删除临时表,以减少系统表资源的消耗。
22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29.尽量避免大事务操作,提高系统并发能力。
30.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
所有由suliang20发布的文章
Linux基本权限
一、文件基本权限
1、基本权限的修改
-rw-r--r-- -- '-' 文件类型('-' 文件 'd' 目录 'l' 软链接文件) -- rw- r-- r-- u所有都 g所属组 o其他人 -- 'r' 读 'w' 写 'x' 执行
chmod 命令
[root@localhost ~]# chmod [选项] 模式 文件名 选项: -- -R:递归 模式: -- [ugoa] [+-=] [rwx] -- [mode=421]
修改权限的方式
[root@localhost ~]# chmod u+x cangls.av #给文件所有者加执行权限 [root@localhost ~]# chmod g+w,o+w furong.av #给所有组及其他加写入权限 [root@localhost ~]# chmod a=rwx fengjie.av #给所有人加读、写、执行权限
权限的数字表示
-- r --- 4 -- w --- 2 -- x --- 1 rwxr-xr-x 7 5 5
2、权限的作用
1)权限对文件的作用
r:读取文件内容(cat more head tail) w:编辑、新增、修改文件内容(vi echo) -- 但是不包含删除文件 x:可执行
2)权限对目录的作用
r:可以查询目录下文件名(ls) w:具有修改目录结构的权限。如新建文件和目录,删除此目录下文件和目录,重命名此目录下文件和目录,剪切(touch rm mv cp) x:可以进入目录(cd)
3、其他权限命令
1)修改文件的所有者
[root@localhost ~]# chown 用户名 文件名 例: [root@localhost ~]# chown ds fengj.av
2)修改文件的所属组
[root@localhost ~]# chgrp 组名 文件名 例如: [root@localhost ~]# chgrp group1 fengj.av
3)让用户对文件及目录拥有一定的权限
要求:
— 拥有一个test目录
— 让某用户拥有所有的权限
— 让另一用户有查看权限
— 其他所有人不许查看这个目录
二、文件默认权限
1、查看默认权限的命令
umask
#查看默认权限
0022 -- 第一位0:文件特殊权限 -- 022:文件默认权限
2、文件的默认权限
#文件默认不能建立为执行文件,必须手工赋予执行权限
#所有文件默认权限最大为666
#默认权限需要换算成字母再相减
#建立文件之后的默认权限,为666减去umask值
例如: -- 文件默认最大权限666 umask值022 -- -rw-rw-rw- 减去 -----w--w- 等于 -rw-r--r-- 例如 -- 文件默认最大权限666 umask值033 -- -rw-rw-rw- 减去 -----wx-wx 等于 -rw-r--r--
3、目录的默认权限
# 目录默认权限最大为777
# 默认权限需要换算成字母再相减
# 建立文件之后的默认权限,为777减去umask值
例如:
-- 目录默认最大权限为777 umask值022 -- -rwxrwxrwx 减去 -----w--w- 等于 -rwxr-xr-x
4、修改umask值
# 临时修改
[root@localhost ~]# umask 0002
# 永久修改
[root@localhost ~]# vi /etc/profile
三、ACL权限
1、ACL权限简介与开启
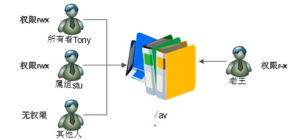
1)ACL权限简介
2)查看分区ACL权限是否开启
[root@localhost ~]# dumpe2fs -h /dev/sda5 Default mount options: user_xattr acl #dumpe2fs命令是查询指定分区详细文件系统信息的命令 选项: -- -h:仅显示超级块中信息,而不显示磁盘块组的详细信息
3)临时开启分区ACL权限
[root@localhost ~]# mount -o remount,acl / #重新挂载根分区,并挂载加入acl权限
4)永久开启分区ACL权限
[root@localhost ~]# vi /etc/fstab UUID=22029318-ae20-4bbd-b520-ce5d6fd8d4d5 / ext4 defaults 1 1 # 加入acl UUID=22029318-ae20-4bbd-b520-ce5d6fd8d4d5 / ext4 defaults,acl 1 1 [root@localhost ~]# mount -o remount / # 重新挂载文件系统或重启动系统,使修改生效
2、查看与设定ACL权限
1)查看ACL命令
[root@localhost ~]# getfacl 文件名 # 查看acl权限
2)设定ACL权限的命令
[root@localhost ~]# setfacl 选项 文件名 选项: -- -m:设定ACL权限 -- -x:删除指定的ACL权限 -- -b:删除所有的ACL权限 -- -d:设定默认ACL权限 -- -k:删除默认ACL权限 -- -R:递归设定ACL权限
3)给用户设定ACL权限
例
[root@localhost ~]# useradd tony [root@localhost ~]# groupadd stu [root@localhost ~]# mkdir /av [root@localhost ~]# chown tony:stu /av [root@localhost ~]# chmod 770 /av [root@localhost ~]# useradd lw [root@localhost ~]# setfacl -m u:lw:rx /av # 给用户lw赋予r-x权限,使用"u:用户名:权限"格式
4)给用户组设定ACL权限
[root@localhost ~]# groupadd tgroup2 [root@localhost ~]# setfacl -m g:tgroup2:rwx /av # 为组tgroup2分配ACL权限。使用"g:组名:权限"格式
3、最大有效权限与删除ACL权限
1)最大有效权限mask
# mask是用来指定最大有效权限的。如果我给用户赋予了ACL权限,是需要和mask的权限”相与“才能得到用户的真正权限
修改最大有效权限
[root@localhost ~]# setfacl -m m:rx 文件名 # 设定mask权限为r-x。使用“m:权限”格式
2)删除ACL权限
[root@localhost ~]# setfacl -x u:用户名 文件名 # 删除指定用户的ACL权限 [root@localhost ~]# setfacl -x g:组名 文件名 # 删除指定用户组的ACL权限 [root@localhost ~]# setfacl -b 文件名 # 会删除文件的所有的ACL权限
4、默认ACL权限和递归ACL权限
1)递归ACL权限
递归是父目录在设定ACL权限时,所有的子文件和子目录也会拥有相同的ACL权限。
# setfacl -m u:用户名:权限 -R 目录名
默认ACL权限的作用是如果给父目录设定了默认ACL权限,那么父目录中所有新建的子文件都会继承父目录的ACL权限。
# setfacl -m d:u:用户名:权限 目录名
四、sudo权限
1、sudo权限
# root把本来只能超级用户执行的命令赋予普通用户执行。
# sudo的操作对象是系统命令
2、sudo使用
[root@localhost ~]# visudo # 实际修改的是/etc/sudoers文件 root ALL=(ALL) ALL #用户名 被管理主机的地址=(可使用的身份) 授权命令(绝对路径) # %wheel ALL=(ALL) ALL # %组名 被管理主机的地址=(可使用的身份) 授权命令(绝对路径)
五、文件特殊权限
1、SetUID
1)SetUID的功能
只有可以执行的二进制程序才能设定SUID权限
命令执行要对该程序拥有x(执行)权限
命令执行者在执行该程序时获得该程序文件属主的身份(在执行程序的过程中灵魂附体为文件的属主)
SetUID权限只在该程序执行过程中有效,也就是说身份改变只在程序执行过程中有效
2)设定SetUID的方法
4代表SUID -- chmod 4755 文件名 -- chmod u+s 文件名
passwd命令拥有SetUID权限,所以普通用户可以修改自己的密码
[root@localhost ~]# ll /usr/bin/passwd -rwsr-xr-x. 1 root root 30768 2月 22 2012 /usr/bin/passwd
cat命令没有SetUID权限,所以普通用户不能查看/etc/shadow文件内容
[root@localhost ~]# ll /bin/cat -rwxr-xr-x. 1 root root 45224 11月 22 2013 /bin/cat
3)取消SetUID的方法
chmod 0755 文件名
或
chmod u-s 文件名
4)危险的SetUID
# 关键目录应严格控制写权限。比如”/”、”/usr”等
# 用户的密码设置要严格遵守密码三原则
# 对系统中默认应该具有SetUID权限的文件作一列表,定时检查有没有这之外的文件被设置了SetUID权限
新建suid权限文件列表suid.log
[root@localhost ~]# find / -perm -4000 -o -perm -2000 > suid.log
suid_check.sh
#!/bin/bash
find / -perm -4000 -o -perm -2000 > /tmp/setuid.check
#搜索系统中所有拥有SUID和SGID的文件,并保存在临时目录中
for i in $(cat /tmp/setuid.check)
#做循环,每次循环取出临时文件中的文件名
do
grep $i /root/suid.log > /dev/null
#对比这个文件名是否在模板文件中
if [ "$?" != "0" ]
#检测上一个命令的返回值,如果不为0,证明上一个命令报错
then
echo `date +"%Y-%m-%d %H:%M:%S"` "$i isn't in listfile!" >> /root/suid_log_$(date +%F)
#如果文件名不再模板文件中,则输出错误信息,并把报错记录到日志中
fi
done
rm -rf /tmp/setuid.check
#删除临时文件
2、SetGID
1)SetGID针对文件的作用
# 只有可执行的二进制程序才能设置SGID权限
# 命令执行者要对该程序拥有(执行)权限
# 命令执行在执行程序的时候,组身份升级为该程序文件属组
# SetGID权限同样只在该程序执行过程中有效,也就是说组身份改变只在程序执行过程中有效
2)SetGID针对目录的作用
# 普通用户必须对此目录拥有r和x权限,才能进入此目录
# 普通用户在些目录中的有效组会变成此目录的属组
# 若普通用户对此目录拥有w权限时,新建的文件的默认属组是这个目录的属组
3、Sticky BIT
1)SBIT粘着位作用
# 粘着位目前只对目录有效
# 普通用户对该目录拥有w和x权限,即普通用户可以在些目录拥有写入权限
# 如果没有粘着位,因为普通用户拥有w权限,所以可以删除此目录下所有文件,包括其他用户建立的文件。一但赋予了粘着位,除了root可以删除所有文件,普通用户就算拥有w权限,也只能删除自己建立的文件,但是不删除其他用户建立的文件
2)设置与取消粘着位
设置粘着位
— chmod 1755 目录名
— chmod o+t 目录名
取消粘着位
— chmod 0777 目录名
— chmod o-t 目录名
六、不可改变位权限
Linux软件安装管理
一、软件包管理简介
1、软件包分类
1)源码包
#脚本安装包
2)二进制包(RPM包、系统默认包)
2、源码包
源码包的优点是:
— 开源,如果有足够的能力,可以修改源代码
— 可以自由选择所需的功能
— 软件是编译安装,所以更加适合自己的系统,更加稳定也效率更高
— 卸载方便
源码包的缺点
— 安装过程步骤较多,尤其安装较大的软件集合时(如LAMP环境搭建),容易出现拼写错误
— 编译过程时间较长,安装比二进制安装时间长
— 因为是编译安装,安装过程中一旦报错新手很难解决
3、RPM包
二进制包的优点:
— 包管理系统简单,只通过几个命令就可以实现包的安装、升级、查询和卸载
— 安装速度比源码包安装快的多
二进制包缺点:
— 经过编译,不再可以看到源代码
— 功能选择不如源码包灵活
— 依赖性
4、脚本安装包
所谓的脚本安装包,就是把复杂的软件包安装过程写成了程序脚本,初学者可以执行程序脚本实现一键安装。但实际安装还是源码包和二进制包
— 优点:安装简单、快捷
— 缺点:完全丧失了自定义性
二、RPM命令管理
1、RPM包命名规则
1)RPM包的来源
RPM包在系统光盘中(Packages)
2)RPM包命令原则
httpd-2.2.15-15.el6.centos.1.i686.rpm
— httpd软件包名
— 2.2.15软件版本
— 15软件发布的次数
— el6.centos适合的Linux平台
— i686适合的硬件平台
— rpm rpm包扩展名
3)RPM包依赖性
— 树形依赖:a->b->c
— 环形依赖:a->b->c->a
— 模块依赖:模块依赖,查询网站:www.rpmfind.net
2、安装命令
1)包全名与包名
包全名:操作的包是没有安装的软件包时,使用包命名。而且要注意路径
包名:操作已经安装的软件包时,使用包名,是搜索/var/lib/rpm/中的数据库
2)RPM安装
rpm -ivh 包全名
选项:
— -i(install):安装
— -v(verbose):显示详细信息
— -h(hash):显示进度
— –nodeps:不检测依赖性
3、升级
rpm -Uvh 包全名
选项:
— -U(upgrade):升级
4、卸载
rpm -e 包名
选项:
— -e(erase):卸载
— –nodeps:不检查依赖性
5、RPM包查询
1)查询是否安装
rpm -q 包名
#查询包是否安装
— -q(query):查询
rpm -qa
#查询所有已经安装的RPM包
— -a(all):所有
2)查询软件包详细信息
rpm -qi 包名
选项:
— -i(information):查询软件信息
— -p(package):查询未安装包信息
3)查询包中文件安装位置
rpm -ql 包名
选项:
— -l(list):列表
— -p(package):查询未安装包信息
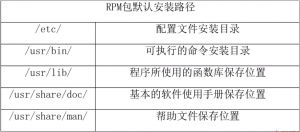
RPM包默认安装位置
4)查询系统文件属于哪个RPM包
rpm -qf 系统文件名
选项:
— -f(file):查询系统文件属性于哪个软件包
5)查询软件包的依赖性
rpm -qR 包名
选项:
— -R(requires):查询软件包的依赖性
— -p(package):查询未安装包信息
6、RPM包校验
1)RPM包校验
rpm -V 已安装的包名
选项:
— -V(verify):校验指定RPM包中的文件
验证内容中的8个信息的具体内容如下:
— S:文件大小是否改变
— M:文件的类型或文件的权限(rwx)是否被改变
— 5:文件MD5校验和是否改变(可以看成文件内容是否改变)
— D:设备的主从代码是否改变
— L:文件路径是否改变
— U:文件的属主(所有者)是否改变
— G:文件的属组是否改变
— T:文件的修改时间是否改变
文件类型
— c(config file):配置文件
— d(documentation):普通文档
— g(ghost file):”鬼“文件,很少见,就是该文件不应该被这个RPM包包含
— L(license file):授权文件
— r(read me):描述文件
2)RPM包中文件提取
rpm2cpio 包全名 | cpio -idv .文件绝对路径
— rpm2cpio
#将rpm包转换为cpio格式的命令
— cpio
#是一个标准工具,它用于创建软件档案文件和从档案文件中提取文件
[root@localhost ~]# cpio 选项 < [文件|设备] 选项: -- -i:copy-in模式,还原 -- -d:还原时自动新建目录 -- -v:显示还原过程 [root@localhost ~]# rpm -qf /bin/ls #查询ls命令属于哪个软件包 [root@localhost ~]# mv /bin/ls /tmp/ #造成ls命令误删除假象 [root@localhost ~]# rpm2cpio /mnt/cdrom/Packages/coreutils-8.4-19.el6.i686.rpm | cpio -idv ./bin/ls #提取RPM包中ls命令到当前目录的/bin/ls下 [root@localhost ~]# cp /root/bin/ls /bin/ #把ls命令复制回/bin/目录,修复文件丢失
三、yum在线管理
1、Yum源文件
[root@localhost ~]# vi /etc/yum.repos.d/CentOS-Base.repo -- [base]:容器名称,一定要放在[]中 -- name:容器说明,可以自己随便写 -- mirrorlist:镜像站点,这个可以注释掉 -- baseurl:我们的yum源服务的地址。默认是CentOS官方的yum源服务器,是可以使用的,如果你觉得慢可以改成你喜欢的yum源地址 -- enabled:此容器是否生效,如果不写或写成enable=1都是生效,写成enable=0就是不生效 -- gpgcheck:如果是1是指RPM的数字证书生效,如果是0则不生效 -- gpgkey:数字证书的公钥文件保存位置,不用修改
2、光盘搭建yum源
1)挂载光盘
[root@localhost ~]# mkdir /mnt/cdrom #建立挂载点 [root@localhost ~]# mount /dev/cdrom /mnt/cdrom/ #挂载光盘
2)使用网络yum源失效
[root@localhost ~]# cd /etc/yum.repos.d/ #进入yum源目录 [root@localhost ~]# mv CentOS-Base.repo CentOS-Base.repo.bak #修改yum源文件后缀名,使其失效
3)使光盘yum源生效
[root@localhost ~]# vim CentOS-Media.repo
[c6-media]
name=CentOS-$releasever - Media
baseurl=file:///media/CentOS/ #地址改为你自己的光盘挂载地址如:file:///mnt/cdrom
file:///media/cdrom/
file:///media/cdrecorder/ #注释这两个不存在的地址
gpgcheck=1
enabled=0 #把enabled=0改为enabled=1,让这个yum源配置文件生效
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
3、yum命令
1)常用yum命令
(1)查询
yum list #查询所有可用软件包列表 yum search关键字 #搜索服务器上所有和关键字相关的包
(2)安装
[root@localhost ~]# yum -y install 包名 选项: -- install:安装 -- -y:自动回答yes 例如: [root@localhost ~]# yum -y install gcc
(3)升级
[root@localhost ~]# yum -y update 包名 选项: -- update:升级 -- -y:自动回答yes
(4)卸载
[root@localhost ~]# yum -y remove 包名 选项: -- remove:卸载 -- -y:自动回答yes
2、YUM软件组管理命令
[root@localhost ~]# yum grouplist #列出所有可用的软件组列表 [root@localhost ~]# yum groupinstall 软件组名 #安装指定软件组,组名可以由grouplist查询出来 [root@localhost ~]# yum groupremove 软件组名 #卸载指定软件组
四、源码包管理
1、源码包和RPM包的区别
1)安装之前的区别:概念上的区别
2)安装之后的区别:安装位置不同
3)源码包安装位置
#安装在指定位置当中,一般是
/usr/local/软件名/
4)安装位置不同带来的影响
#RPM包安装的服务可以使用系统服务管理命令(service)来管理,例如RPM包安装的apache的启动方法是
[root@localhost ~]# /etc/rc.d/init.d/httpd start 或 [root@localhost ~]# service httpd start #service命令是redhat系统专有的命令
#而源码包安装的服务则不能被服务管理命令管理,因为没有安装到默认路径中。所以只能用绝对路径进行服务的管理,如:
[root@localhost ~]# /usr/local/apache2/bin/apachectl start
2、源码包安装过程
1)安装准备
#安装C语言编译器
#下载源码包
— http://mirror.bit.edu.cn/apache/httpd/
2)安装注意事项
#源代码保存位置:/usr/local/src/
#软件安装位置:/usr/local/
#如何确定安装过程报错:
— 安装过程停止
— 并出现error、warning或no的提示
3)源码包安装过程
#下载源码包 #解压缩下载的源码包 [root@localhost ~]# tar -zxvf httpd-2.2.9.tar.gz #进入解压缩目录 [root@localhost ~]# cd httpd-2.2.9 #./configure 软件配置与检查 -- 定义需要的功能选项。 -- 检测系统环境是否符合安装要求。 -- 把定义好的功能选项和检测系统环境的信息都写入Makefile文件,用于后续的编译。 [root@localhost ~]# ./configure --prefix=/usr/local/apache2 #指定安装路径 [root@localhost ~]# make #预编译 [root@localhost ~]# make clean #如果出错使用这个清除编译 [root@localhost ~]# make install #编译安装
五、脚本安装包
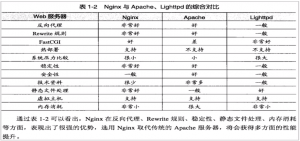
强大的Nginx服务器
#Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POPS)代理服务器,由俄国公司在2004年发布
准备工作
#关闭RPM包安装的httpd和MySQL
#保证yum源正常使用
#关闭SELinux和防火墙
[root@localhost ~]# vi /etc/selinux/config SELINUX=enforcing #改为 SELINUX=disabled #关闭SELinux
下载LAMP
http://lnmp.org/install.html
#脚本一键安装包 [root@localhost ~]# wget -c http://soft.vpser.net/lnmp/lnmp1.0-full.tar.gz && tar zxvf lnmp1.0-full.tar.gz && cd lnmp1.0-full && ./centos.sh
centos.sh脚本分析
#所谓的一键安装包,实际上还是安装的源码包与RPM包,只是把安装过程写成了脚本,便于初学者安装
#优点:简单、快速、方便
#缺点:
— 不能定义安装软件的版本
— 不能定义所需要的软件功能(源码包的优势丧失)
Linux下查看、关闭及开启防火墙命令
Linux下查看、关闭及开启防火墙命令
1)永久性生效,重启后不会复原
开启: chkconfig iptables on 关闭: chkconfig iptables off
2)即时生效,重启后复原
开启: service iptables start 关闭: service iptables stop
需要说明的是对于Linux下的其它服务都可以用以上命令执行开启和关闭操作。
在开启了防火墙时,做如下设置,开启相关端口, 修改/etc/sysconfig/iptables 文件,添加以下内容:
-A RH-Firewall-1-INPUT -m state –state NEW -m tcp -p tcp –dport 80 -j ACCEPT
-A RH-Firewall-1-INPUT -m state –state NEW -m tcp -p tcp –dport 22 -j ACCEPT
3)查看防火墙状态
chkconfig iptables –list
条件判断与流程控制
一、流程控制语句
1、条件判断式
1)按照文件类型进行判断

两种判断格式
[root@localhost ~]# test -e /root/install.log [root@localhost ~]# [ -e /root/install.log ]
简单的判断式
[root@localhost ~]# [ -d /root ] && echo "yest" || echo "no" #第一个判断命令如果正确执行,则打印"yes",否则打印"no"
2)按照文件权限进行判断
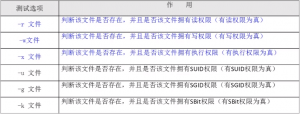
[root@localhost ~]# [ -w student.txt] && echo "yes" || echo "no" #判断文件是拥有写权限的
3)两个文件之间进行比较

[root@localhost ~]# ln /root/student.txt /tmp/stu.txt #创建硬链接 [root@localhost ~]# [ /root/student.txt -ef /tmp/stu.txt] && echo "yes" || echo "no" #判断两个文件是否为同一个文件
4)两个整数之间的比较

[root@localhost ~]# [ 23 -ge 22 ] && echo "yes" || echo "no" #判断23是否大于等于22 [root@localhost ~]# [ 23 -le 22 ] && echo "yes" || echo "no" #判断23是否小于等于22
5)字符串的判断
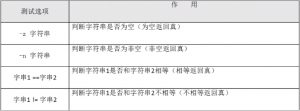
[root@localhost ~]# name=fengj @给name变量赋值 [root@localhost ~]# [ -z "$name" ] && echo "yes" || echo "no" #判断name变量是否为空 [root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和变量bb赋值 [root@localhost ~]# [ "$aa" == "bb" ] && echo "yes" || echo "no" #判断两个变量的值是否相等
6)多重条件判断

[root@localhost ~]# aa=11 [root@localhost ~]# [ -n "$aa" -a "$aa" -gt 23 ] && echo "yes" || echo "no" #判断变量aa是否有值,同时判断变量aa的是否大于23 #因为变量aa的值不大于23,所以虽然第一个判断值为真,返回的结果也是假
2、单分支if语句
单分支if条件语句
if [ 条件判断式 ];then 程序 fi #或者 if [ 条件判断式 ] then 程序 fi
单分支条件语句需要注意几个点
#if语句使用fi结尾,和一般语言使用大括号结尾不同
#[ 条件判断式 ]就是使用test命令判断,所以中括号和条件判断式之间必须有空格
#then后面跟符合条件之后执行的程序,可以放在[]之后,用”;”分割。也可以换行写入,就不需要”;”了
例子1:判断登陆的用户是否为root
#!/bin/bash test=$(env | grep "USER" | cut -d "=" -f 2) if [ "$test" == root] then echo "Current user is root." fi
例子2:判断分区使用率
#!/bin/bash
#统计根分区使用率
#把根分区使用率作为变量值赋予变量rate
rate=$(df -h | grep "/dev/sda3" | awk '{print $5}' | cut -d "%" -f 1)
if [ $rate -ge 80 ]
then
echo "Warning! /dev/sda3 is full!!"
fi
3、双分支if语句
双分支if条件语句
if [ 条件判断式 ]
then
条件成立时,执行的程序
else
条件不成立时,执行的另一个程序
fi
例子1:判断输入的是否是一个目录
#!/bin/bash
#判断输入的文件是否是一个目录
read -t 30 -p "Please input a directory: " dir
if [ -d $dir ]
then
echo "yes"
else
echo "no"
fi
例子2:判断apache是否启动
#!/bin/bash
#截取httpd进程,并把结果赋予变量test
test=$(ps aux | grep httpd | grep -v grep)
if [ -n "$test" ]
#如果test的值不为空,则执行then中命令
then
echo "$(date) httpd is ok!" >> /tmp/autostart-acc.log
else
/etc/rc.d/init.d/httpd start &> /dev/null
echo "$(date) restart httpd !!" >> /tmp/autostart-err.log
fi
4、多分支if语句
多分支if条件语句
if [ 条件判断式1 ]
then
当条件判断式1成立时,执行程序1
elif [ 条件判断式2 ]
then
当条件判断式2成立时,执行程序2
...省略更多条件
else
当所有条件都不成立时,最后执行此程序
fi
例子
#!/bin/bash
#字符界面加减乘除计算器
read -t 30 -p "Please input num1: " num1
read -t 30 -p "Please input num2: " num2
#通过read命令接收要计算的数值,并赋予变量num1和num2
read -t 30 -p "Please input a operator: " ope
if [ -n "$num1" -a -n "$num2" -a -n "$ope" ]
#第一层判断,用来判断num1,num2和ope中都有值
then
test1=$(echo $num1 | sed 's/[0-9]//g')
test2=$(echo $num2 | sed 's/[0-9]//g')
#定义变量test1和test2的值为$(命令)的结果
#后续命令作用是,把变量test1的值替换为空。如果能替换为空,证明num1的值为数字
#如果不能替换为空,证明num1的值为非数字。我们使用这种方法判断变量num1的值为数字
#用同样的方法测试test2变量
if [ -z "$test1" -a -z "$test2" ]
#第二层判断,用来判断num1和num2为数值
#如果变量test1和test2的值为空,则证明num1和num2是数字
then
#如果test1和test2是数字,则执行以下命令
if [ "$ope" == '+' }
#第三层判断用来确认运算符
#测试变量$ope中是什么运算符
then
sum=$(( $num1 + $num2))
#如果是加号则执行加法运算
elif [ "$ope" == '-' ]
then
sum=$(($num1 - $num2))
#如果是减号,则执行减法运算
elif [ "$ope" == '*' ]
then
sum=$(( $num1 * $num2))
#如果是乘号,则执行乘法运算
elif [ "$ope" == '/' ]
then
sum=$(( $num1 / $num2))
#如果除号,则执行除法运算
elif [ "$ope" == '%' ]
then
sum=$(( $num1 % $num2))
#如果是取模,则执行取模运算
else
echo "Please enter a valid symbol"
#如果运算符不匹配,提示输入有效的符号
exit 10
#并退出程序,返回错误代码10
fi
elif
#如果test1和test2不为空,说明num1和num2不是数字
echo "Please enter a valid value"
#则提示输入有效的数值
exit 11
#并退出程序,返回错误代码11
fi
elif
echo "qing shuru neirong"
exit 12
fi
echo " $num1 $ope $num2 : $num"
#输出数值运算的结果
例子:从1加到100
#!/bin/bash
#从1加到100
s=0
for(( i=1;i<=100;i=i+1 ))
do
s=$(( $s+$i))
done
echo "The sum of 1+2+...+100 is: $s"
例子:批量添加指定数量的用户
#!/bin/bash
#批量添加指定数量的用户
read -p "Please input user name: " -t 30 name
read -p "Please input the number of users: " -t 30 num
read -p "Please input the password of users: " -t 30 pass
if [ ! -z "$name" -a ! -z "$num" -a ! -z "$pass"]
then
y=$(echo $num | sed 's/[0-9]//g')
if [ -z "$y" ]
then
for(( i=1;i<=$num;i=i+1 )) do /usr/sbin/useradd $name$i &>/dev/null
echo $pass | /usr/bin/passwd --stdin $name$i &>/dev/null
done
fi
fi
5、case语句
多分支case条件语句
#case语句和if..elif..else语句一样都是多分支条件语句,不过和if多分支条件语句不同的是,case语句只能判断一种条件关系,而if语句可以判断多种条件关系。
case $变量名 in
"值1")
如果变量的值等于值1,则执行程序1
;;
"值2")
如果变量的值等于值2,则执行程序2
;;
...省略其他分支
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
6、for循环
语法一:
for 变量 in 值1 值2 值3 ...
do
程序
done
例子:批量解压脚本
#!/bin/bash
#批量解压缩脚本
cd /root/test
ls *.tar.gz > /tmp/ls.log
for i in $(cat ls.log)
do
tar -zxf $i &>/dev/null
done
rm -rf /tmp/ls.log
语法二
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
7、while循环和until循环
1)while循环
while循环是不定循环,也称作条件循环。只要条件判断式成立,循环就会一直继续,直到条件判断式不成立,循环才停止。这就和for的固定循环不太一样了。
while [ 条件判断式 ]
do
程序
done
2)until循环
# until循环,和while循环相反,until循环时只要条件判断式不成立则进行循环,并执行循环程序。一旦循环条件成立,则终止循环。
until [ 条件判断式 ]
do
程序
done
Shell正则表达式
一、正则表达式
1、正则表达式是什么
#正则表达式是用于描述字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分割、匹配、查找及替换操作。
2、正则表达式与通配符
#正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed等命令可以支持正则表达式。
#通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配了
通配符
— * 匹配任意内容
— ? 匹配任意一个内容
— [] 匹配中括号中的一个字符
3、基础正则表达式
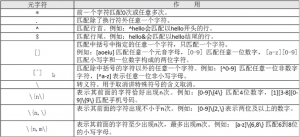
1)”.”匹配除了换行符任意一个字符
"s..d" #"s..d"会匹配在s和d这两个字母之间一定有两个字符的单词 "s.*d" #匹配s和d字母之间有任意字符 ".*" #匹配所有内容
2)”^”匹配行首,”$”匹配行尾
"^M" #匹配以大写“M”开头的行 "n$" #匹配以小写"n"结尾的行 "^$" #会匹配空白行
3)”[]”匹配中括号中指定的任意一个字符,只匹配一个字符
"s[ao]id" #匹配s和i字母中,要不是a、要不是o "[0-9] #匹配任意一个数字 "^[a-z]" #匹配用小写字母开头的行
4)”[^]”匹配除中括号的字符以外的任意一个字符
"^[^a-z]" #匹配不用小写字母开头的行 "^[^a-aA-Z]" #匹配不用字母开头的行
5)”\”转义符
"\.$" #匹配使用"."结尾的行
6)”\{n\}”表示其前面的字符恰好出现n次
"a\{3\}"
#匹配a字母连接出现三次的字符串
"[0-9]\{3\}"
#匹配包含连续的三个数字的字符串
7)”\{n,\}表示其前面的字符出现不小于n次
"^[0-9]\{3,\}[a-z]
#匹配最少用连续三个数字开头的行
8)”\{n,m\}”匹配其前面的字符至少出现n次,最多出现m次
"sa\{1,3\}i"
#匹配在字母s和字母i之间有最少一个a,最多三个a
4、例子
[0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}
#匹配日期格式YYYY-MM-DD
[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}
#匹配IP地址
二、字符截取命令
1、cut字段提取命令
[root@localhost ~]# cut [选项] 文件名
选项:
— -f 列号:提取第几列
— -d 分隔符:按照指定分隔符分割列
cut命令的局限
— df -h | cut -d ” ” -f 1,3
2、printf命令
printf ‘输出类型输出格式’ 输出内容
输出类型:
— %ns:输出字符串。n是数字指代输出几个字符
— %ni:输出整数。n是数字指代输出几个数字
— %m.nf:输出浮点数。m和n是数字,指代输出的整数位数和小数位数如%8.2f代表共输出8位数,其中2位是小数,6位是整数。
输出格式:
— \a:输出警告声音
— \b:输出退格键,也就是Backspace键
— \f:清除屏幕
— \n:换行
— \r:回车,也就是Enter键
— \t:水平输出退格键,也就是Tab键
— \v:垂直输出退格键,也就是Tab键
例:
[root@localhost ~]# printf %s 1 2 3 4 5 6 [root@localhost ~]# printf %s %s %s 1 2 3 4 5 6 [root@localhost ~]# printf '%s %s %s' 1 2 3 4 5 6 [root@localhost ~]# printf '%s %s %s\n' 1 2 3 4 5 6 [root@localhost ~]# printf '%s' $(cat student.txt) #不调整输出格式 [root@localhost ~]# printf '%s\t%s\t%s\t%s\n $(cat student.txt) #调整格式输出
在awk命令的输出中支持print和printf命令
— print:print会在每个输出之后自动加入一个换行符(Linux默认没有print命令)
— printf:printf是标准格式输出命令,并不会自动加入换行符,如果需要换行,需要手工加入换行符
3、awk命令
# awk ‘条件1{动作1} 条件2{动作2}…’ 文件名
条件(Pattern)
— 一般使用关系表达式作为条件
— x>10判断变量 x是否大于10
— x>=10大于等于
— x<=10小于等于
动作(Action)
— 格式化输出
— 流程控制语句
例:
[root@localhost ~]# vim student.txt
student.txt content
ID Name gender Mark
1 furong F 85
2 fengj F 60
3 cang F 70
[root@localhost ~]# awk '{printf $2 "\t" $4 "\n"}' student.txt
[root@localhost ~]# df -h | awk '{print $1 "\t" $3}'
BEGIN
[root@localhost ~]# awk ‘BEGIN{printf “This is a transcript \n”} {printf $2 “\t” $4 “\n”}’ student.txt
END
[root@localhost ~]# awk ‘END{printf “The End\n”} {printf $2 “\t” $4 “\n”}’ student.txt
FS内置变量
[root@localhost ~]# cat /etc/passwd | grep “/bin/bash” | awk ‘BEGIN{FS=”:”}{printf $1 “\t” $3 “\n”}’
关系运算符
[root@localhost ~]# cat student.txt | grep -v Name | awk ‘$4>=70{printf $2 “\n”}’
4、sed命令
#sed 是一种几乎包括在所有UNIX平台(包括Linux)的轻量级流编辑器。sed主要是用来将数据进行选取、替换、删除、新增的命令。
sed [选项] '[动作]' 文件名 选项: -- -n:一般sed命令会把所有数据都输出到屏幕,如果加入此选择则只会把经过sed命令处理的行输出到屏幕。 -- -e:允许对输入数据应用多条sed命令编辑 -- -i:用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出。
动作:
— a:追加,在当前行后添加一行或多行
— c:行替换,用c后面的字符串替换原数据行
— i:插入,在当前行行前插入一行或多行。
— d:删除,删除指定的行
— p:打印,输出指定的行。
— s:字串替换,用一个字符串替换另外一个字符串。格式为“行范围s/旧字串/新字串/g”(和vim中的替换格式类似)。
行数据操作
[root@localhost ~]# sed '2p' student.txt #查看文件的第二行 [root@localhost ~]# sed -n '2p' student.txt #查看文件的第二行,且只显示第二行 [root@localhost ~]# sed '2,4d' student.txt #删除第二行到第四行的数据,但不修改文件本身 [root@localhost ~]# sed '2a piaoliang jiushi renxing' student.txt #在第二行后追加 [root@localhost ~]# sed '2i meinv' student.txt #在第二行前插入两行数据 [root@localhost ~]# sed '2c furong bu ji ge' student.txt #数据替换
字符串替换
sed ‘s/旧字串/新字串/g’ 文件名
[root@localhost ~]# sed '3s/60/99/g' student.txt #在第三行中,把60换成99 [root@localhost ~]# sed -i '3s/60/99/g' student.txt #sed操作的数据直接写入文件 [root@localhost ~]# sed -e 's/fengj//g;s/cang//g' student.txt #同时把"fengj"和"cang"替换为空
三、字符处理
1、排序命令sort
[root@localhost ~]# sort [选项] 文件名
选项:
— -f:忽略大小写
— -n:以数值型进行排序,默认使用字符串型排序
— -r:反向排序
— -t:指定分隔符,默认是分隔符是制表符
— -k n[,m]:按照指定的字段范围排序。从第n字段开始,m字段结束(默认到行尾)
[root@localhost ~]# sort /etc/passwd #排序用户信息文件 [root@localhost ~]# sort -r /etc/passwd #反向排序 [root@localhost ~]# sort -t ":" -k 3,3 /etc/passwd #指定分隔符是":",用第三字段开头,第三字段结尾排序,就是只用第三字段排序 [root@localhost ~]# sort -n -t ":" -k 3,3 /etc/passwd
2、统计命令wc
[root@localhost ~]# wc [选项] 文件名
选项:
— -l:只统计行数
— -w:只统计单词数
— -m:只统计字符数
Shell环境变量配置文件
一、环境变量配置文件简介
1、source命令
[root@localhost ~]# source 配置文件 或 [root@localhost ~]# .配置文件
注:修改配置文件后,必须注销重新登录才能生效,使用source命令可以不用重新登录
例:
[root@localhost ~]# . .bashrc 或 [root@localhost ~]# source .bashrc
2、环境变量配置文件简介
PATH、HISTSIZE、PS1、HOSTNAME等环境变量写入对应的环境变量配置文件
环境变量配置文件中主要是定义对系统操作环境生效的系统默认环境变量,如PATH等
— /etc/profile
— /etc/profile.d/*.sh
— ~/.bash_profile
— ~/.bashrc
— /etc/bashrc
二、环境变量配置文件的功能
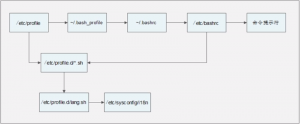
1、/etc/profile的作用:
USER变量:
LOGNAME变量:
MAIL变量:
PATH变量:
HOSTNAME变量:
HISTSIZE变量
umask:
调用/etc/profile.d/*.sh文件
2、umask权限
#查看系统默认权限
注意:
1)文件最高权限为666
2)目录最高权限为777
3)权限不能使用数据进行换算,而必须使用字母
4)umask定义的权限,是系统默认权限中准备丢弃的权限
3、~/.bash_profile的作用
调用了~/.bashrc文件。
在PATH变量后面加入了”:$HOME/bin”这个目录
4、~/.bashrc的作用
定义默认别名
调用/etc/bashrc
5、/etc/bashrc的作用
PS1变量
umask
PATH变量
调用/etc/profile.d/*.sh文件
三、其他配置文件
1、注销时生效的环境变量配置文件
~/.bash_logout
2、命令历史记录文件
~/.bash_history
3、Shell登录信息
1)本地终端欢迎信息:/etc/issue

2)远程终端欢迎信息:/etc/issue.net
#转义符在/etc/issue.net文件中不能使用
#是否显示此欢迎信息,由ssh的配置文件/etc/ssh/sshd_config决定,加入”Banner /etc/issue.net”行才能显示(记得重启SSH服务)
3)登录后欢迎信息:/etc/motd
#不管是本地登录,还是远程登录,都可以显示此欢迎信息
Shell运算符
一、declare命令
1、declare声明变量类型
— [root@localhost ~]# declare [+/-][选项] 变量名
选项:
— -:给变量设定类型属性
— +:取消变量的类型属性
— -a:将变量声明为数组型
— -i:将变量声明为整数型(integer)
— -x:将变量声明为环境变量
— -r:将变量声明为只读变量
— -p:显示指定变量的被声明类型
2、变量声明为数值型
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和bb赋值
[root@localhost ~]# declare -i cc=$aa+$bb #声明变量cc的类型是整数型,它的值是aa和bb的和
3、声明数组
#定义数组
[root@localhost ~]# movie[0]=zp
[root@localhost ~]# movie[1]=tp
[root@localhost ~]# declare -a movie[2]=live
#查看数组
[root@localhost ~]# echo ${movie}
[root@localhost ~]# echo ${movie[2]}
[root@localhost ~]# echo ${movie[*]}
4、声明环境变量
declare -x test =123
#和export作用相似,但其实是declare命令的作用
5、声明变量只读属性
[root@localhost ~]# declare -r test
#给test赋予只读属性,但是请注意只读属性会让变量不能修改不能删除,甚至不能取消只读属性
6、查询变量的属性
declare -p
#查询所有变量的属性
declare -p 变量名
#查询指定变量的属性
二、数值运算的方法
1、数值运算方法1
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和bb赋值 [root@localhost ~]# declare -i cc=$aa+$bb
2、方法2:expr或let数值运算工具
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 #给变量aa和变量bb赋值 [root@localhost ~]# dd=$(expr $aa + $bb) #dd的值是aa和bb的和。注意”+“号左右两侧必须有空格
3、方法3:”$((运算式))” 或 “$[运算式]”
[root@localhost ~]# aa=11 [root@localhost ~]# bb=22 [root@localhost ~]# ff=$(($aa+$bb)) [root@localhost ~]# gg=$[$aa+$bb]
4、运算符
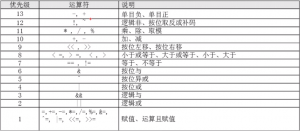
例:
[root@localhost ~]# aa=$(((11+3)*3/2)) #虽然乘和除的优先级高于加,但是通过小括号可以调整运算优先级 [root@localhost ~]# bb=$((14%3)) #14不能被3整除,余数是2 [root@localhost ~]# cc=$((1&&0)) #逻辑与运算只有想与的两边都是1,与的结果才是1,否则与的结果是0
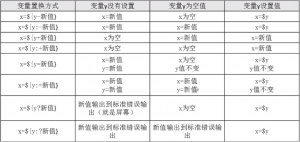
三、变量测试
Shell变量
一、什么是变量与变量分类
1、什么是变量
# 变量是计算机内存的单元,其中存放的值可以改变
# 变量让你能够把程序中准备使用的每一段数据都赋给一个简短、易于记忆的名字,因此它们十分有用。
2、变量命名规则
# 变量名必须以字母或下划线打头,名字中间只能由字母、数字和下划线组成。
# 变量名的长度不得超过255个字符。
# 变量名在有效的范围内必须是唯一的。
# 在Bash中,变量的默认类型都是字符串型
3、变量按照存储数据分类
# 字符串型
# 整型
# 浮点型
# 日期型
4、变量的分类
# 用户自定义变量。变量自定义的
# 环境变量:这种变量中主要保存的是和系统操作环境相关的数据。变量可以自定义,但是对系统生效的环境变量名和变量作用是固定的
# 位置参数变量:这种变量主要是用来向脚本当中传递参数或数据的,变量名不能自定义,变量作用是固定的
# 预定义变量:是Bash中已经定义好的变量,变量名不能自定义,变量作用也是固定的
二、用户自定义变量
1、定义变量
变量名=变量值(等号前后不能有空格)
例如:
— x=5
— name=”jie cao”
2、变量调用
echo $变量名
例如:
— echo $x
— echo $name
3、变量叠加
— x=123
— x=”$x”456
— x=${x}789
4、变量查看
set
选项
— u:如果设定此选项,调用未声明变量时会报错(默认无任何提示)
5、变量删除
unset 变量名
三、环境变量
1、环境变量与用户自定义变量的区别?
# 环境变量和用户自定义变量最主要的区别在于,环境变量是全局变量,而用户自定义变量是局部变量。用户自定义变量只在当前的Shell中生效,而环境变量会在当前Shell和这个Shell的所有子Shell当中生效
# 变量可以自定义,但是对系统生效的环境变量名和变量作用是固定的
— [root@localhost ~]# pstree
# 查看进程树
2、设置环境变量
export 变量名=变量值
或
变量名=变量值
export 变量名
3、查看环境变量
set
# 查看所有变量
env
# 查看环境变量
4、删除环境变量
unset 变量名
5、常用环境变量
— HOSTNAME:主机名
— SHELL:当前的shell
— TERM:终端环境
— HISTSIZE:历史命令条数
— SSH_CLIENT:当前操作环境是用ssh连接的,这里记录客户端ip
— SSH_TTY:ssh连接的终端时pts/1
— USER:当前登录的用户
6、PATH环境变量
PATH变量:系统查找命令的路径
— echo $PATH
# 查看PATH环境变量
— PATH=”$PATH”:/root/sh
#增加PATH变量的值
7、PS1环境变量
PS1变量:命令提示符设置
— \d:显示日期,格式为”星期 月 日“
— \H:显示完整的主机名。如默认主机名”localhost.localdomain”
— \t:显示24小时制时间,格式为”HH:MM:SS”
— \A:显示24小时制时间,格式为”HH:MM”
— \u:显示当前用户名
— \w:显示当前所在目录的完整名称
— \W:显示当前所在目录的最后一个目录
— \$:提示符。如果是root用户会显示提示符为”#”,如果是普通用户会显示提示符为”$”
例:
— [root@localhost ~]# PS1='[\u@\A \w]\$ ‘
8、当前语系查询
locale
# 查询当前系统语系
— LANG:定义系统主语系的变量
— LC_ALL:定义整体语系的变量
9、语系变量LANG
echo $LANG
# 查看系统当前语系
locale -a | more
# 查看Linux支持的所有语系
10、查询系统默认语系
cat /etc/sysconfig/i18n
11、Linux中文支持
前提条件,正确安装的中文字体和中文语系
# 如果有图形界面,可以正确支持中文显示
# 如果使用第三方远程工具,只要语系设定正确,可以支持中文显示
# 如果使用纯字符界面,必须使用第三方插件(如zhcon等)
四、位置参数变量
1、位置参数变量
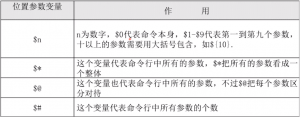
例子1:
#!/bin/bash num1=$1 num2=$2 sum=$(($num1+$num2)) #变量sum的和是num1加num2 echo $sum #打印变量sum的值
例子2
#!/bin/bash echo "A total of $# parameters" #使用$#代表所有参数的个数 echo "The parameters is:$*" #使用$*代表所有的参数 echo "The parameters is:$@" #使用$@也代表所有参数
例子3:$*与$@的区别
#!/bin/bash
for i in "$*"
#$*中的所有参数看成是一个整体,所以这个for循环只会循环一次
do
echo "The parameters is $i"
done
for y in "$@"
#$@中的每个参数都看成是独立的,所以"$@"中有几个参数,就会循环几次
do
echo "Parameter:$y"
done
五、预定义变量
1、预定义变量

2、接收键盘输入
read [选项] [变量名]
选项:
— -p “提示信息”:在等待read输入时,输出提示信息
— -t 秒数:read命令会一直等待用户输入,使用此选项可以指定等待时间
— -n 字符数:read命令只接受指定的字符数,就会执行
— -s:隐藏输入的数据,适用于机密信息的输入
用户管理
一、用户和用户组的概念
用户:使用操作系统的人
用户组:具有相同系统权限的一组用户
/etc/group 存储当前系统中所有用户组信息
— Group: x : 123 : abc,def,xyz
— 组名称:组密码占位符:组编号:组中用户名列表
/etc/gshadow 存储当前系统中用户组的密码信息
— Group : * : : abc,def,xyz
— 组名称:组密码:组管理者:组中用户名列表
/etc/passwd 存储当前系统中所有用户的信息
— user : x : 123 : 456 : xxxxxxx : /home/user : /bin/bash
— 用户名:密码占位符:用户编号:用户组编号:用户注释信息:用户主目录:shell类型
/etc/shadow 存储当前系统中所有用户的密码信息
— user :vf;/Zu8sdf..:::::
— 用户名:密码:::::
二、用户和用户组的基本命令
groupadd 用户组
#添加用户组
例:
— [root@localhost ~]# groupadd sexy
groupmod -n 新用户组名 旧用户组名
#修改用户组名
例:
— [root@localhost ~]# groupmod -n market sexy
groupmod -g 用户组编号 用户组名称
#修改用户组编号
例:
— [root@localhost ~]# groupmod -g 668 market
groupadd -g 用户组编号 用户组名称
#创建新用户,并指定编号
例:
— [root@localhost ~]# groupadd -g 888 boss
groupdel 用户组名称
#删除用户组
例:
— [root@localhost ~]# groupdel market
注:删除用户组前需要先删除或转移当前用户组的用户
useradd -g 用户组名称 用户名
#添加新用户并指定的用户组
例:
— [root@localhost ~]# useradd -g sexy sdf
useradd -d 用户文件夹 用户名
#添加新用户并指定用户文件夹
例:
— [root@localhost ~]# useradd -d /home/xxx imooc
注:添加新用户时,如果没有指定用户组,会对应生成与用户名相同的用户组
usermod -c 用户备注 用户名
#给用户添加注释
例:
— [root@localhost ~]# usermod -c dgdzmx sdf
usermod -l 新用户名 旧用户名
#修改用户名
例:
— [root@localhost ~]# usermod -l cls sdf
usermod -d 用户文件夹 用户名
#给用户指定新用户文件夹
例:
— [root@localhost ~]# usermod -d /home/cls cls
usermod -g 用户组 用户名
#给用户指定用户组
例:
— [root@localhost ~]# usermod -g sexy imooc
userdel 用户名
#删除用户
例:
— [root@localhost ~]# userdel jzmb
userdel -r 用户名
#删除用户同时删除用户文件夹
例:
— [root@localhost ~]# userdel -r jzmb
touch /etc/nologin
#禁止除了root外的所有用户登录,只要在/etc/下建立nologin文件,文件不包含任何内容
三、用户和用户组进阶命令
passwd -l 用户名
#锁定用户
例:
— [root@localhost ~]# passwd -l cls
passwd -u 用户名
#解锁用户名
例:
— [root@localhost ~]# passwd -u cls
passwd -d 用户名
#清除用户密码
例:
— [root@localhost ~]# passwd -d cls
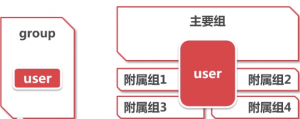
主要组与附属组
用户可以同时属于多个组
— 一个主要组
— 多个附属组
gpasswd -a 用户 附属组名称
#给用户添加附属组
例:
— [root@localhost ~]# gpasswd -a cls boss
newgrp 用户组
#用户切换用户组
例:
— [root@localhost ~]# newgrp boss
gpasswd -d 用户名 用户组
#把用户从某用户组中移除
例:
— [root@localhost ~]# gpasswd -d cls boss
useradd -g 主用户组 -G 附属用户组1,附属用户组2… 用户名
#新建用户,并指定用户组及附属用户组
例:
— [root@localhost ~]# useradd -g group1 -G group2,group3… test
gpasswd 用户组名称
#设置用户组密码
例:
— [root@localhost ~]# gpasswd imooc
四、其他命令
su 用户名
#切换用户
例:
— [root@localhost ~]# su username
注:如果只输入su不输入用户名,表示切换到root用户
whoami
#我是谁?显示当前登陆用户名
id 用户名
#显示指定用户信息,包括用户编号、用户名、主要组编号及名称,附属组列表
例:
— [root@localhost ~]# id imooc
groups 用户名
#显示指定用户所在的所有组
例:
— [root@localhost ~]# groups imooc
chfn 用户名
#设置用户资料,依次输入用户资料
例:
— [root@localhost ~]# chfn imooc
finger 用户名
#显示用户详细资料
例:
— [root@localhost ~]# finger imooc