1、将文件checkout到本地目录
svn checkout path(path是服务器上的目录)
例如:svn checkout svn://192.168.1.1/pro/domain
简写:svn co
2、往版本库中添加新的文件
svn add file
例如:svn add test.php(添加test.php)
svn add *.php(添加当前目录下所有的php文件)
3、将改动的文件提交到版本库
svn commit -m “LogMessage“ [-N] [–no-unlock] PATH(如果选择了保持锁,就使用–no-unlock开关)
例如:svn commit -m “add test file for my test“ test.php
简写:svn ci
4、加锁/解锁
svn lock -m “LockMessage“ [–force] PATH
例如:svn lock -m “lock test file“ test.php
svn unlock PATH
5、更新到某个版本
svn update -r m path
例如:
svn update如果后面没有目录,默认将当前目录以及子目录下的所有文件都更新到最新版本。
svn update -r 200 test.php(将版本库中的文件test.php还原到版本200)
svn update test.php(更新,于版本库同步。如果在提交的时候提示过期的话,是因为冲突,需要先update,修改文件,然后清除svn resolved,最后再提交commit)
简写:svn up
6、查看文件或者目录状态
1)svn status path(目录下的文件和子目录的状态,正常状态不显示)
【?:不在svn的控制中;M:内容被修改;C:发生冲突;A:预定加入到版本库;K:被锁定】
2)svn status -v path(显示文件和子目录状态)
第一列保持相同,第二列显示工作版本号,第三和第四列显示最后一次修改的版本号和修改人。
注:svn status、svn diff和 svn revert这三条命令在没有网络的情况下也可以执行的,原因是svn在本地的.svn中保留了本地版本的原始拷贝。
简写:svn st
7、删除文件
svn delete path -m “delete test fle“
例如:svn delete svn://192.168.1.1/pro/domain/test.php -m “delete test file”
或者直接svn delete test.php 然后再svn ci -m ‘delete test file‘,推荐使用这种
简写:svn (del, remove, rm)
8、查看日志
svn log path
例如:svn log test.php 显示这个文件的所有修改记录,及其版本号的变化
9、查看文件详细信息
svn info path
例如:svn info test.php
10、比较差异
svn diff path(将修改的文件与基础版本比较)
例如:svn diff test.php
svn diff -r m:n path(对版本m和版本n比较差异)
例如:svn diff -r 200:201 test.php
简写:svn di
11、将两个版本之间的差异合并到当前文件
svn merge -r m:n path
例如:svn merge -r 200:205 test.php(将版本200与205之间的差异合并到当前文件,但是一般都会产生冲突,需要处理一下)
12、SVN 帮助
svn help
svn help ci
——————————————————————————
以上是常用命令,下面写几个不经常用的
——————————————————————————
13、版本库下的文件和目录列表
svn list path
显示path目录下的所有属于版本库的文件和目录
简写:svn ls
14、创建纳入版本控制下的新目录
svn mkdir: 创建纳入版本控制下的新目录。
用法: 1、mkdir PATH…
2、mkdir URL…
创建版本控制的目录。
1、每一个以工作副本 PATH 指定的目录,都会创建在本地端,并且加入新增
调度,以待下一次的提交。
2、每个以URL指定的目录,都会透过立即提交于仓库中创建。
在这两个情况下,所有的中间目录都必须事先存在。
15、恢复本地修改
svn revert: 恢复原始未改变的工作副本文件 (恢复大部份的本地修改)。revert:
用法: revert PATH…
注意: 本子命令不会存取网络,并且会解除冲突的状况。但是它不会恢复
被删除的目录
16、代码库URL变更
svn switch (sw): 更新工作副本至不同的URL。
用法: 1、switch URL [PATH]
2、switch –relocate FROM TO [PATH…]
1、更新你的工作副本,映射到一个新的URL,其行为跟“svn update”很像,也会将
服务器上文件与本地文件合并。这是将工作副本对应到同一仓库中某个分支或者标记的
方法。
2、改写工作副本的URL元数据,以反映单纯的URL上的改变。当仓库的根URL变动
(比如方案名或是主机名称变动),但是工作副本仍旧对映到同一仓库的同一目录时使用
这个命令更新工作副本与仓库的对应关系。
17、解决冲突
svn resolved: 移除工作副本的目录或文件的“冲突”状态。
用法: resolved PATH…
注意: 本子命令不会依语法来解决冲突或是移除冲突标记;它只是移除冲突的
相关文件,然后让 PATH 可以再次提交。
18、输出指定文件或URL的内容。
svn cat 目标[@版本]…如果指定了版本,将从指定的版本开始查找。
svn cat -r PREV filename > filename (PREV 是上一版本,也可以写具体版本号,这样输出结果是可以提交的)
所有由suliang20发布的文章
PhpStorm 快捷键大全 PhpStorm 常用快捷键和配置
PhPStorm 是 JetBrains 公司开发的一款商业的 PHP 集成开发工具,PhpStorm可随时帮助用户对其编码进行调整,运行单元测试或者提供可视化debug功能。Phpstrom的一款名为Magicento的插件对快速创建Magento插件十分有用。
常用快捷键
设置快捷键:File -> Settings -> IDE Settings -> Keymap -> 选择“eclipse” -> 然后“Copy”一份 -> 再个性化设置(自己习惯的)快捷键
常用快捷键(keymaps:Default情况下)
Esc键编辑器(从工具窗口)
F1 帮助 千万别按,很卡!
F2(Shift+F2) 下/上高亮错误或警告快速定位
F3 向下查找关键字出现位置
F4 查找变量来源
F5 复制文件/文件夹
F6 移动
F11 切换书签
F12 返回到以前的工具窗口
注意:部分快捷键,必须在没有更改快捷键的情况下才可以使用
查询快捷键
CTRL+N 查找类
CTRL+SHIFT+N 查找文件,打开工程中的文件(类似于eclipse中的ctrl+shift+R),目的是打开当前工程下任意目录的文件
CTRL+SHIFT+ALT+N 查 找类中的方法或变量(JS)
CIRL+B 找变量的来源,跳到变量申明处
CTRL+ALT+B 找所有的子类
CTRL+SHIFT+B 找变量的 类
CTRL+G 定位行,跳转行
CTRL+F 在当前窗口查找文本
CTRL+SHIFT+F 在指定路径查找文本
CTRL+R 当前窗口替换文本
CTRL+SHIFT+R 在指定路径替换文本
ALT+SHIFT+C 查找修改的文件,最近变更历史
CTRL+E 最近打开的文件
F3 查找下一个
SHIFT+F3 查找上一个
F4 查找变量来源
CTRL+ALT+F7 选 中的字符 查找工程出现的地方
ALT+F7 直接查询选中的字符
Ctrl+F7 文件中查询选中字符
自动代码
ALT+回车 导入包,自动修正
CTRL+ALT+L 格式化代码
CTRL+ALT+I 自动缩进
CTRL+ALT+O 优化导入的类和包
CTRL+E 最近更改的文件/代码
CTRL+SHIFT+SPACE 切换窗口
CTRL+SPACE空格 代码自动完成,代码提示,一般与输入法冲突
CTRL+ALT+SPACE 类 名或接口名提示(与系统冲突)
CTRL+P 方法参数提示,显示默认参数
CTRL+J 自动代码提示,自动补全
CTRL+ALT+T 把选中的代码放在 TRY{} IF{} ELSE{} 里
ALT+INSERT 生成代码(如GET,SET方法,构造函数等)
复制快捷方式
F5 复制文件/文件夹
CTRL+C 复制
CTRL+V 粘贴
CTRL+X 剪 切,删除行
CTRL+D 复制行
Ctrl + Y 删除行插入符号
CTRL+SHIFT+V 可以复制多个文本
高亮
CTRL+F 选中的文字,高亮显示 上下跳到下一个或者上一个
F2(Shift+F2) 高亮错误或警告快速定位
SHIFT+F2 高亮错误或警告快速定位
CTRL+SHIFT+F7 高亮显示多个关键字.
本地历史VCS/SVN
Alt +反引号(’) 快速弹出VCS菜单
Ctrl + K 提交项目VCS
Ctrl + T 更新项目从VCS
Alt + Shift + C 查看最近发生的变化
其他快捷方式
CTRL+Z 倒退(代码后悔)
CTRL+SHIFT+Z 向前
CTRL+H 显 示类结构图
Ctrl +F12 文件结构弹出
Ctrl+Shift+H 方法的层次结构
Ctrl+Alt+H 呼叫层次
CTRL+Q 显示代码注释
CTRL+W 选中代码,连续按会 有其他效果
Ctrl+Shift+W 减少当前选择到以前的状态
CTRL+B 转到声明,快速打开光标处的类或方法说明注释(CTRL + 鼠标单击 也可以)
CTRL+O 魔术方法
CTRL+/ 注释//取消注释
CTRL+SHIFT+/ 注释/*…*/
CTRL+ [] 光标移动到 {}[]开头或结尾位置
CTRL+SHIFT+[] 选中块代码,可以快速复制
ctrl + ‘-/+’: 可以折叠项目中的任何代码块,包括htm中的任意nodetype=3的元素,function,或对象直接量等等。它不是选中折叠,而是自动识别折叠。
ctrl + ‘.’: 折叠选中的代码的代码
Ctrl+Shift+U 选中的字符大小写转换
ctrl+shift+i 快速查看变量或方法定义源
CTRL+ALT+F12 资源管理器打开文件夹,跳转至当前文件在磁盘上的位置
ALT+F1 选择当前文件或菜单中的任何视图工具栏
SHIFT+ALT+INSERT 竖编辑模式
CTRL+ALT ←/→ 返回上次编辑的位置
ALT+ ←/→ 切换代码视图,标签切换
ALT+ ↑/↓ 在方法间快速移动定位
alt + ‘7’: 显示当前的类/函数结构。类似于eclipse中的outline的效果。试验了一下,要比aptana的给力一些,但还是不能完全显示prototype下面的方法名。
SHIFT+F6 重命名,重构 当前区域内变量重命名/重构
不但可以重命名文件名,而且可以命名函数名,函数名可以搜索引用的文件,还可以重命名局部变量。还可以重命名标签名。在sublime text中有个类似的快捷键:ctrl+shift+d。
ctrl+shift+enter(智能完善代码 如 if())
ctrl+shift+up/down(移动行、合并选中行,代码选中区域 向上/下移动)
CTRL+UP/DOWN 光标跳转到编辑器显示区第一行或最后一行下
ESC 光标返回编辑框
SHIFT+ESC 光 标返回编辑框,关闭无用的窗口
CTRL+F4 关闭当前的编辑器或选项卡
Ctrl + Alt + V引入变量
Ctrl + Alt + F 类似引入变量
Ctrl + Alt + C引入常量
Ctrl + Tab 键切换选项卡和工具窗口
Ctrl + Shift + A 查找快捷键
Alt + #[0-9] 打开相应的工具窗口
Ctrl + Shift + F12 切换最大化编辑器
Alt + Shift + F 添加到收藏夹
Alt + Shift + I 检查当前文件与当前的配置文件
Ctrl +反引号(`) 快速切换目前的配色/代码方案/快捷键方案/界面方案
Ctrl + Alt + S 打开设置对话框(与QQ冲突)
运行
Alt + Shift + F10 选择的配置和运行
Alt + Shift + F9 选择配置和调试
Shift + F10 运行
Shift + F9调试
Ctrl + Shift + F10运行范围内配置编辑器
Ctrl + Shift + X运行命令行
调试
F8步过
F7步入
Shift + F7智能进入
Shift + F8步骤
ALT + F9运行到光标
Alt + F8计算表达式
F9恢复程序
Ctrl + F8切换断点
Ctrl + Shift + F8查看断点
导航
Shift + Esc键隐藏活动或最后一个激活的窗口
Ctrl + Shift + F4关闭活动运行/消息/ / …选项卡
Ctrl + Shift + Backspace键导航到最后编辑的位置
Ctrl + Alt+B 到实施(S)
Ctrl + Shift+I 打开快速定义查询
Ctrl + U 转到super-method/super-class
Alt + Home 组合显示导航栏
书签
Ctrl + F11切换书签助记符
Ctrl +#[0-9]转到编号书签
Shift + F11显示书签
编辑
Ctrl + Q 快速文档查询
ALT + INSERT 生成的代码…器(getter,setter方法,构造函数)
Ctrl + O 覆盖方法
Ctrl + I 实现方法
Alt + Enter 显示意图的行动和快速修复
Shift + Tab 键缩进/取消缩进选中的行
Ctrl + Shift + J 智能线连接(仅适用于HTML和JavaScript)
Ctrl + Enter 智能线分割(HTML和JavaScript)
Shift + Enter 开始新的生产线
Ctrl + Delete 删除字(word)
Ctrl + Backspace删除字开始
Ctrl +小键盘+ / – 展开/折叠代码块
Ctrl + Shift +小键盘+展开全部
Ctrl + Shift +数字键盘关闭全部
如下图
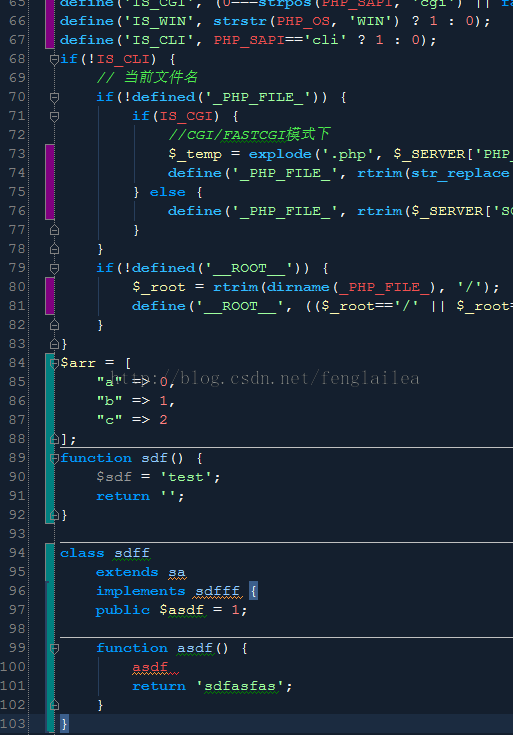
1.界面中文方框问题
Settings->Appearance中
Theme 设置 Windows
勾选Override default fonts by (not recommended),设置字体为宋体
2.显示行号
Settings->Editor->Appearance标签项,勾选Show line numbers
3.光标不随意定位
Settings->Editor中去掉Allow placement of caret after end of line。
4.启动的时候不打开工程文件
Settings->General去掉Reopen last project on startup.
5.无法起动Tomcat( IntelliJ IDEA)
请使用ZIP版的Tomcat
6.快捷键问题
可以使用其他软件的快捷键,
Settings->Keymap
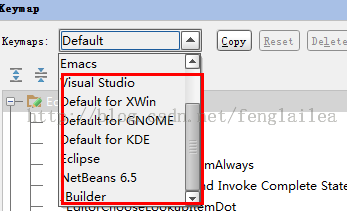
7.快捷键冲突(自己修改)
默认代码提示和补全快捷键跟输入法冲突,如何解决:Settings->Keymap
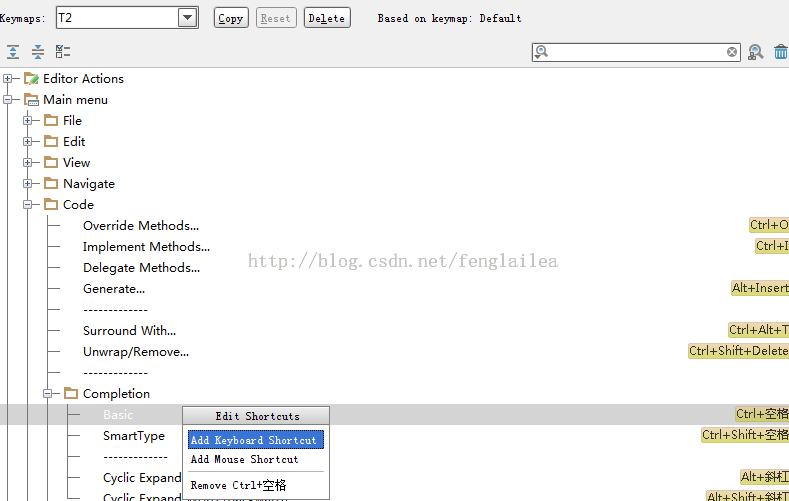
在上面面的图中,点击COPY ,自己新建一个方案,如 T1
然后开始设置快捷键,修改时,右击会弹出菜单,如下图,改成你想要的快捷键
8.用*标识编辑过的文件
Editor –> Editor Tabs
选中Mark modifyied tabs with asterisk
9.编码设置:编辑器中中文乱码问题
这个是项目字符编码设置错误
FILE ->Settings-> 有3处设置根据自己需要设置
IDE Encondings:IDE编码 ,选择 IDE Encoding为GBK。这边要自己去调整了
Project Encoding:项目编码
Default encoding for properties files:默认文件编码
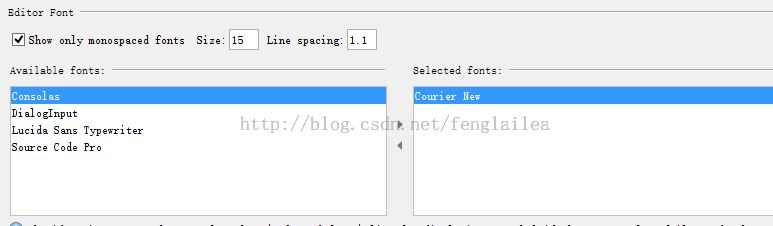
10.编辑器中字体和大小
FILE -> Settings> Editor->Colors & Fonts -> Font -> 右侧
Size:字体大小
Line spacing:行间距
下框中是字体,左侧->可选择字体,右侧->实际应用字体
11.显示文件夹或文件过滤
File->Setting->File Types->Ignore file and folders
里面填写你要的过滤不显示的
注意大小写哦
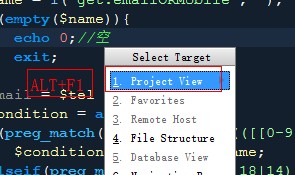
12.当前编辑文件定位
方法1) 在编辑的所选文件按ALT+F1, 然后选择PROJECT VIEW
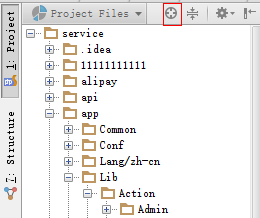
方法2) 左侧 项目列表框 顶部的 定位图标
13.优化文件保存
File->Settings->General->
Synchronize file on frame activation:个人需要是否取消同步文件
Save files on framedeactivation:取消
Save files automatically:选中,设置自动保存,设置 30秒自动保存时间,这样IDEA依然可以自动保持文件,所以在每次切换时,你需要按下Ctrl+S保存文件
14.SVN设置
Setting->Version control-> 右侧 VCS 下面选择 Subversion
网络上比较流行的PHPStorm注册码:
用户名:EMBRACE
注册码:
===== LICENSE BEGIN =====
11674-12042010
0000064nA0kkqI8qwPBF1rebuLP2Js
Shb1n3EDL6mUr9LnhpxzMTxV”zZNjA
DVi1nwUvh7UuZ8FGwaN8WejHHHtFop
===== LICENSE END =====
用户名:EMBRACE
注册码:
===== LICENSE BEGIN =====
11674-12042010
0000064nA0kkqI8qwPBF1rebuLP2Js
Shb1n3EDL6mUr9LnhpxzMTxV”zZNjA
DVi1nwUvh7UuZ8FGwaN8WejHHHtFop
===== LICENSE END =====
二、大型网站缓存介绍及灾难预警
缓存
在计算机系统中,缓存有很多种。比如CPU内部的一级缓存、二级缓存。文件系统的缓存,磁盘的缓存。在大型网站的后台部署过程中,也灵活运用了各级缓存。主要有客户端的浏览器缓存,服务器端的web server自身缓存,代理缓存,分布式缓存,数据库自身的缓存等。
缓存分类及优势
一、本地缓存 和应用服务争夺内存 速度快
二、远程缓存 理论上内存不受限制(分布式缓存)速度较本地慢
1、Squid功能全而大,适合于各种静态的文件缓存,国内的top2CDN厂商是基于拿squid做的商业改造,但受限于仅支持单进程(虽然squid3.2也开始支持SMP了:http://wiki.squid-cache.org/Features/SmpScale),因此一般会在前端挂一个HAProxy或nginx做负载均衡跑多个实例。
2、Varnish由于是内存cache,所以对小文件如css,js,小图片的支持很好,sina就是用的varnish,后端的持久化缓存可能采用的是squid或ats
3、nginx的代理功能只是它的一个模块功能,功能相对前两者目前还完全无法替代,但未来充满期待。
4、还有apache trafficserver,专业的代理,相对squid,它支持多cpu,国内阿里,youku,sina等厂商都在用,感兴趣可以去Apache Traffic Server ATS

三、缓存面临的问题
一致性和实时性
一个很直观的场景就是,数据库中的数据状态已经改变,但是用户在页面上看到的仍然是缓存的旧值。
一般来说,缓存数据本身都是保持在内存中的,例如淘宝内部大量使用tair系统(已开源)。tair拥有若干服务器,这些服务器内存都很大,可以存放大量数据。当然,考虑到内存的易失性,tair一般来说不能存放重要的数据。
Tair:http://tair.taobao.org/
四、什么样的数据可以放缓存
1、不需要实时更新但是又极其消耗数据库的数据。比如统计数据,排行榜。
2、js,css,image等文件
3、使用频率很高的一些程序对象。
五、缓存灾难
故障现象:没有新应用发布,但是数据库服务器突然Load飙升,并很快失去响应。DBA将数据库访问切换到备机,Load也很快飙升,并失去响应。最终引发网站全部瘫痪。
原因分析:缓存服务器在网站服务器集群中的地位一直比较低,服务器配置和管理级别都比其他服务器要低一些。人们都认为缓存是改善性能的手段,丢失一些缓存也没有什么问题,有时候关闭一两台缓存服务器也确实对应用没有明显影响,所以长期疏于管理。结果这次一个缺乏经验的工程师关闭了缓存服务器集群中全部的十几台Memcached服务器,导致了网站全部瘫痪的重大事故。
经验:当缓存已经不仅仅是改善性能,而是成为网站架构不可或缺的一部分时,对缓存的管理就需要提高到和其他服务器一样的级别。
一、大型网站架构重点
1、高性能
响应时间,TPS,系统性能计数器等。缓存,消息队列等。
2、高可用性High Availability 99.99% 7×24
衡量标准:假设环境中一台或多台服务器宕机,服务是否依然可用。
解决关键办法:冗余。资源定位,健康检查、负载均衡,关键服务器主备冗余–WEB DB,及时有效的监控和报警
3、高伸缩性[高可维护性]
是否可以用多台服务器构建集群,是否容易向集群添加新服务器,新服务是否可提供相同的服务,总服务器是否有限制。
4、高扩展性
网站添加新的业务时是否可以实现对现有产品透明无影响,不需要做任何改动。数据库切片,基础模块独立服务(用户系统)等。
5、高安全性
针对现在的攻击及窃密否有良好的策略应对。
linux+apache+php+mysql源代码安装
安装的过程整体要分为三大过程:
安装apache 和 mysql
安装PHP
安装 memcached php-memcache
安装apache 和 mysql
第一步 下载apache mysql;并且为二者建立对应的安装目录
#mkdir –p /opt/soft
#cd /opt/soft
#wget http://download.chyangwa.com/linux/apache/httpd-2.2.4.tar.gz
#wget http://download.chyangwa.com/linux/MySQL/mysql-5.0.19.tar.gz
#mkdir –p /usr/local/apache
#mkdir –p /usr/local/mysql
第二步 解压以及安装apache
#tar –zxvf httpd-2.2.4.tar.gz
#tar –zxvf mysql-5.0.19.tar.gz
#cd httpd-2.2.4
#./configure –prefix=/usr/local/apache –enable-so –enable-rewrite –enable-deflate –with-mpm=worker
#make && make install
#make clean
#cd
启动服务:
#/usr/local/apache/bin/apachectl –k start
然后在地址栏里面输入:本机IP/index.html 如果可以看到“It works!”就说明apache已经安装成功了
第三步 解压以及安装mysql
//建立数据库的用户和用户组:
# groupadd mysql
# useradd -g mysql mysql
//编译安装数据库:
#cd mysql-5.0.19
#./configure –prefix=/usr/local/mysql –with-extra-charsets=complex –enable-thread-safe-client –enable-local-infile –enable-assembler –disable-shared –with-client-ldflags=-all-static –with-mysqld-ldflags=-all-staticm –with-embedded-server –with-innodb –with-extra-charsets=gbk,gb2312,big5 –without-debug CFLAGS=-O3 -mcpu=pentium4 CXXFLAGS=-O3 -march=pentium4 -felide-constructors -fno-exceptions -fno-rtti CXX=gcc
# make && make install
# make clean
# cp -r mysql-5.0.19 /usr/local/mysql
# cp support-files/mysql.server /etc/rc.d/init.d/mysql
# cp support-files/my-medium.cnf /etc/my.cnf
修改mysql目录权限
# chown -R root /usr/local/mysql
# chgrp -R mysql /usr/local/mysql
# chown -R mysql /usr/local/mysql/data
生成mysql系统数据库
# /usr/local/mysql/bin/mysql_install_db –user=mysql&
# /usr/local/mysql/bin/mysqld_safe –user=mysql&
**如出现 Starting mysqld daemon with databases from /usr/local/mysql/data 代表正常启动mysql服务了.
make install结束后,新安装的需要执行bin/mysql_install_db文件来安装授权表,然后运行bin/mysqld_safe启动mysql服务。用mysql命令看是否则连接到服务器。在./configure的时候通常都会出现 checking for termcap functions library… configure: error: No curses/termcap library found这个错误!安装上libncurses5-dev (不同的系统可能名字也有所差异)这个包就好了
$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
安装PHP
第一步 下载需要的组件(可以根据工作需要定制)
# cd /opt/soft
# wget http://download.chyangwa.com/linux/freetype/freetype-2.2.1.tar.gz
# wget http://download.chyangwa.com/linux/GD/gd-2.0.33.tar.gz
# wget http://download.chyangwa.com/linux/zlib/zlib-1.2.3.tar.gz
# wget http://download.chyangwa.com/linux/jpegsrc/jpegsrc.v6b.tar.gz
# wget ftp://ftp.gnu.org/gnu/gdbm/gdbm-1.8.2.tar.gz
# wget http://download.chyangwa.com/linux/gettext/gettext-0.14.5.tar.gz
# wget http://download.chyangwa.com/linux/libiconv/libiconv-1.10.tar.gz
# wget http://download.chyangwa.com/linux/libxml/libxml-1.8.17.tar.gz
# wget http://download.chyangwa.com/linux/PHP/php-5.0.5.tar.gz
# wget http://www.libpng.org/pub/png/libpng.html/libpng-1.2.25.tar.gz
为以上的安装包建立目录
# mkdir –p /usr/local/libxml
# mkdir –p /usr/local/freetype
# mkdir –p /usr/local/gd2
# mkdir –p /usr/local/zlib
# mkdir –p /usr/local/jpeg
# mkdir –p /usr/local/gdbm
# mkdir –p /usr/local/gettext
# mkdir –p /usr/local/libiconv
# mkdir –p /usr/local/libxml
# mkdir –p /usr/local/php
# mkdir –p /usr/local/libpng
第二步 安装PHP相关连的包
a.安装 jpeg6 建立目录:如果选择默认安装,可能很顺利,指定路径后,请先创建以下文件夹
# mkdir –p /usr/local/jpeg6
# mkdir –p /usr/local/jpeg6/bin
# mkdir –p /usr/local/jpeg6/lib
# mkdir –p /usr/local/jpeg6/include
# mkdir –p /usr/local/jpeg6/man
# mkdir –p /usr/local/jpeg6/man1
# mkdir –p /usr/local/jpeg6/man/man1
# cd /opt/soft/
# tar –zvxf jpegsrc.v6b.tar.gz
# cd jpeg6
# ./configure –prefix=/usr/local/jpeg6/ –enable-shared –enable-static
# make
# make install
# make install-lib
# make clean
b.libpng包(支持PNG)
# cd /opt/soft/
# tar –zvxf libpng-(version).tar.gz
# cd libpng-(version)
# ./configure –prefix=/usr/local/libpng
# make
# make install
# make clean
c.安装 freetype
# cd /opt/soft/
# tar –zvxf freetype-2.2.1.tar.gz
# cd freetype-2.2.1
# ./configure –prefix=/usr/local/freetype
# make
# make install
# make clean
d.安装zlib
# cd /root/Software/
# tar –zxvf zlib-1.2.3.tar.gz
# cd zlib.1.2.3
# mkdir /usr/local/zlib
# ./configure –prefix=/usr/local/zlib
# make
# make install
# make clean
e.安装gettext
# cd /opt/soft /
# tar –zxvf gettext-0.14.5.tar.gz
# cd gettext-0.14.5
# ./configure –prefix=/usr/local/gettext
# make
# make install
# make clean
f.安装libxml
# cd /opt/soft /
# tar –zxvf libxml-1.8.17.tar.gz
# cd libxml-1.8.17
# ./configure –prefix=/usr/local/libxml
# make
# make install
# make clean
g.安装gdbm
# cd /opt/soft /
# tar –zxvf gdbm-1.8.2.tar.gz
# cd gdbm-1.8.2
# ./configure –prefix=/usr/local/gdbm
# make
# make install
# make clean
h.安装libiconv
# cd /opt/soft /
# tar –zxvf libiconv-1.10.tar.gz
# cd libiconv-1.10
# ./configure –prefix=/usr/local/libiconv
# make
# make install
# make clean
i.安装gd2
# cd /opt/soft /
# tar –zxvf gd-2.0.33.tar.gz
# cd gd-2.0.33
# ./configure –prefix=/usr/local/gd2 –with-zlib=/usr/local/zlib/ –with-png=/usr/local/libpng/ –with-jpeg=/usr/local/jpeg/ –with-freetype=/usr/local/freetype
# make
# make install
# make clean
第三步 安装PHP
# cd /opt/soft /
# tar –zxvf php-5.0.5.tar.gz
# cd php-5.0.5.tar.gz
# ./configure –prefix=/usr/local/php –with-apxs2=/usr/local/apache/bin/apxs –with-jpeg-dir=/usr/local/jpeg/ –with-gettext –enable-mbstring –with-libxml-dir=/usr/local/libxml –with-png-dir=/usr/local/libpng/ –with-gd=/usr/local/gd2/ –with-freetype-dir=/usr/local/freetype –enable-trace-vars –with-zlib-dir=/usr/local/zlib/ –with-mysql=/usr/local/mysql –with-gdbm-dir=/usr/local/gdbm/ –enable-wddx –with-iconv –enable-sockets –disable-ipv6
# make
# make install
# make clean
# cp php.ini-dist /usr/local/php/lib/php.ini
第四步 修改httpd.conf文件
编辑apache配置文件httpd.conf
#vi /usr/local/apache2/conf/httpd.conf
要改的有如下几处:
1一般都在
#AddType application/x-tar .tgz
下加一行
#LoadModule php5_module modules/libphp5.so
AddType application/x-httpd-php .php
如果搜索其它地方没有以下这行
LoadModule php5_module modules/libphp5.so 把上面的#号去掉
2 找到 DirectoryIndex index.html index.html.var 在后面加 index.php 让它把index.php做为默认页
3 #ServerName 把#去掉,后面的IP改成本机的IP.
第五步 测试
在apache的根目录下面(/usr/local/apache/htdocs)建立一个文件内容为:
<?php
phpinfo();
?>
保存为test.php文件
然后重启apache服务器,进行如下操作
#/usr/local/apache/bin/apachectl –k stop
#/usr/local/apache/bin/apachectl –k start
然后在地址栏里面输入:本机IP/test.php 如果可以看到php的版本以及其他相关信息就说明PHP已经安装成功了
$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
安装 memcached php-memcache
第一步 下载相关组件
#wget http://www.danga.com/memcached/dist/memcached-1.2.2.tar.gz
#wget http://pecl.php.net/package/memcache/memcache-1.2.0.tgz
#wget http://www.monkey.org/~provos/libevent-1.2.tar.gz
第二步 安装组件
libevent-1.2 安装:
默认安装:
# tar –zxvf libevent-1.2.tar.gz
# cd libevent-1.2
# ./configure
# make
# make install
# make clean
建立一个符号连接:
# ls -s /usr/local/lib/libevent-1.2.so.1 /usr/lib 否则memcached无法运行。
memcached-1.2.2 安装,
# tar –zxvf memcached-1.2.2.tar.gz
# cd memcached-1.2.2
# ./configure –prefix=/usr/local/memcached
# make
# make install
# make clean
第三步 安装Memcache的PHP扩展
1.在http://pecl.php.net/package/memcache 选择相应想要下载的memcache版本。
2.安装PHP的memcache扩展
tar vxzf memcache-2.2.1.tgz
cd memcache-2.2.1
/usr/local/php/bin/phpize
./configure –enable-memcache –with-php-config=/usr/local/php/bin/php-config –with-zlib-dir
make
make install
3.上述安装完后会有类似这样的提示:
Installing shared extensions: /usr/local/php/lib/php/extensions/no-debug-zts-20041030/
4.把php.ini中的extension_dir = “./”修改为
extension_dir = “/usr/local/php/lib/php/extensions/no-debug-zts-20041030/”
5.添加一行来载入memcache扩展:extension=memcache.so
memcached的基本设置:
启动Memcache的服务器端:
# /usr/local/bin/memcached -d -m 10 -u root -l 192.168.1.55 -p 12000 -c 256 -P /tmp/memcached.pid
-d选项是启动一个守护进程,
-m是分配给Memcache使用的内存数量,单位是MB;
-u是运行Memcache的用户;
-l是监听的服务器IP地址;
-p是设置Memcache监听的端口,最好是1024以上的端口;
-c选项是最大运行的并发连接数,默认是1024;
-P是设置保存Memcache的pid文件,这里是保存在 /tmp/memcached.pid;
2.如果要结束Memcache进程,执行:
# kill `cat /tmp/memcached.pid`
也可以启动多个守护进程,不过端口不能重复。
3. 然后重启apache服务器,进行如下操作
#/usr/local/apache/bin/apachectl –k stop
#/usr/local/apache/bin/apachectl –k start
Memcache环境测试:
建立一个文件为pptest.php内容如下:
<?php
$mem = new Memcache;
$mem->connect(“127.0.0.1”,11211);
$mem->set(‘key’,’this is a test!’,0,60);
$val = $mem->get(‘key’);
echo $val;
?>
然后在地址栏里面输入:本机IP/pptest.php 如果可以看到this is a test!就说明已经安装成功了
源码安装Apache服务
1.Yum install –y gcc* 安装gcc环境
Yum install –y openssl* 安装openssl软件包
2.下载httpd源码包;
Tar –xzvf httpd-2.2.9.tar.gz –C /usr/src 解压源码包到/usr/src目录中<源码包放置目录>
3.Mkdir –p /usr/local/apache2
4../configure –prefix=/usr/local/apache2 –enable-so 配置编译选项
–enable-rewrite –enable-ssl –with-ssl=/usr/lib
–enable-suexec –with-suexec-caller=daemon
–with-suexec-docroot=/usr/local/apache2
5.Make 编译服务器程序
6.Make install 安装服务器程序
7./usr/local/apache2/bin/apachectl start 启动httpd服务
8./usr/local/apache2/bin/apachectl -t 语法检测
更改httpd启动方式:
1.将http脚本复制到/etc/rc.d/init.d这个目录下:
cp -a apachectl /etc/rc.d/init.d/httpd
2.vi httpd
#chkconfig: 345 70 70
#description: apache
3.添加httpd到启动项:
chkconfig –add httpd
4.查看是否有httpd服务:
chkconfig –list httpd
源码安装后Apache服务器的根目录:
/usr/local/apache2/
日志文件:
/usr/local/apache2/logs/
Httpd主配置文件:
/usr/local/apache2/conf/httpd.conf
Hhttp服务器网页根目录:
/usr/local/apache2/htdocs/
创建虚拟WEB主机:
Cd /usr/local/apache2/htdocs/ 创建虚拟目录benetcom
Mkdir benetcom
Cd benetcom
Cp /usr/local/apache2/htdocs/index.html ./ 创建测试网页
Vi index.html
Cd /usr/local/apache2/conf/ 增加虚拟主机配置
Vi httpd.conf
:r extra/httpd-vhosts.conf
80>
# ServerAdmin webmaster@dummy-host.example.com
DocumentRoot “/usr/local/apache2/docs/benetcom”
ServerName www.benet.com
# ServerAlias www.dummy-host.example.com
ErrorLog “logs/benet.com-error_log”
CustomLog “logs/benet.com-access_log” common
用RPM安装后的Apache配置文件具体位置:
/etc/httpd/ Apache服务程序根目录
/etc/httpd/conf/httpd.conf 主配置文件
/var/www/html 网页文档默认根目录
/var/log/httpd/error_log 错误日志文件
/var/log/httpd/access_log 访问日志文件
VMware虚拟机克隆Linux系统引起的网卡问题
1. 手动配置静态网卡地址不生效
2. 网卡名变成了eth1
[root@localhost network-scripts]# ls |grep ifcfg
ifcfg-eth0
ifcfg-lo
[root@localhost network-scripts]# ifconfig
eth1 Link encap:Ethernet HWaddr 00:0C:29:3A:8B:02
inet addr:192.168.1.134 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe3a:8b02/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:5154 errors:0 dropped:0 overruns:0 frame:0
TX packets:299 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:529420 (517.0 KiB) TX bytes:32319 (31.5 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
[root@localhost network-scripts]# vim ifcfg-eth0
DEVICE=eth0
HWADDR=00:0C:29:52:39:18
TYPE=Ethernet
UUID=d12572cd-6808-4cae-b7b6-5480982206e8
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.119
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
手动设置静态ip地址和网关后,保存退出;然后重启网络后出现错误
[root@localhost network-scripts]# service network restart
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: Error: No suitable device found: no device found for connection ‘System eth0’.
[FAILED]
[root@localhost network-scripts]#
英汉互译
No suitable device found: no device found for connection ‘System eth0’.
没有找到合适的设备:没有找到设备连接的系统eth0”。
总结了以下解决方案
更改ifconfig显示的eth1网卡名为eth0,并设置static ip地址
编辑/etc/udev/rules.d/70-persistent-net.rules文件,把NAME=”eth0″的那行配置注释掉或者删掉,把NAME=”eth1″的修改成NAME=”eth0″,修改后如下:
[root@localhost network-scripts]# vim /etc/udev/rules.d/70-persistent-net.rules
# This file was automatically generated by the /lib/udev/write_net_rules
# program, run by the persistent-net-generator.rules rules file.
#
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
# PCI device 0x8086:0x100f (e1000)
#SUBSYSTEM==”net”, ACTION==”add”, DRIVERS==”?*”, ATTR{address}==”00:0c:29:52:39:18″, ATTR{type}==”1″, KERNEL==”eth*”, NAME=”eth0″
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM==”net”, ACTION==”add”, DRIVERS==”?*”, ATTR{address}==”00:0c:29:3a:8b:02″, ATTR{type}==”1″, KERNEL==”eth*”, NAME=”eth0″
查看以下信息
[root@localhost network-scripts]# ls |grep ifcfg-
ifcfg-eth0
ifcfg-lo
[root@localhost network-scripts]# vim ifcfg-eth0
DEVICE=eth0
HWADDR=00:0c:29:3a:8b:02
TYPE=Ethernet
UUID=d12572cd-6808-4cae-b7b6-5480982206e8
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.119
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
重启启动网卡服务
[root@localhost network-scripts]# service network restart
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: Active connection state: activating
Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/2
state: activated
Connection activated
[ OK ]
[root@localhost network-scripts]# ifconfig
eth1 Link encap:Ethernet HWaddr 00:0C:29:3A:8B:02
inet addr:192.168.1.119 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe3a:8b02/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:3833 errors:0 dropped:0 overruns:0 frame:0
TX packets:273 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:380984 (372.0 KiB) TX bytes:45223 (44.1 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
ECSHOP后台会员列表页增加按手机查询会员功能
1、
首先修改程序文件 admin/users.php
找到
| $filter[‘pay_points_lt’] = empty($_REQUEST[‘pay_points_lt’]) ? 0 : intval($_REQUEST[‘pay_points_lt’]); |
在它下面增加一行代码
| $filter[‘mobile_phone’] = empty($_REQUEST[‘mobile_phone’]) ? 0 : trim($_REQUEST[‘mobile_phone’]); |
继续找到
| if ($filter[‘pay_points_lt’]) { $ex_where .=” AND pay_points < ‘$filter[pay_points_lt]’ “; } |
在它下面增加下列代码
| if ($filter[‘mobile_phone’]) { $ex_where .=” AND mobile_phone like ‘%$filter[mobile_phone]%’ “; } |
2、修改模板文件 admin/templates/users_list.htm
找到
| {$lang.label_user_name} <input type=”text” name=”keyword” /> |
在它后面增加代码
| 手机号码: <input type=”text” name=”mobile_phone” /> |
继续找到
| listTable.filter[‘keywords’] = Utils.trim(document.forms[‘searchForm’].elements[‘keyword’].value); |
在它下面增加一行代码
| listTable.filter[‘mobile_phone’] = Utils.trim(document.forms[‘searchForm’].elements[‘mobile_phone’].value); |
实现Ecshop会员注册成功后就是某种会员特殊等级资格
按照ECSHOP默认的程序,新注册的会员都是“非特殊等级”,
你要想实现你期望的那样的效果,得改注册程序,注册成功的同时自动设置为某个“特殊等级”
关于怎么修改程序,以前有人问过,我记得我回复过,你可以搜索下
=============================================
例如,让会员注册成功后就成为“vip用户”,可以用下面方法修改
修改 includes/lib_passwort.php
在
$update_data = array_merge($update_data, $other);
下面增加一行代码
$update_data['user_rank']=2; //自动注册成“VIP会员”
$GLOBALS['db']->query("update ".$GLOBALS['ecs']->table('user_rank') . "set special_rank =1 where rank_id=2" );
这样修改以后,会员一注册就是“vip用户”了,
php大数据量及海量数据处理算法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题。下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论。
1.Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为 0,则m 应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个 bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。
2.Hashing
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
基本原理及要点:
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。 (http://www.my400800.cn)
扩展:
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例:
1).海量日志数据,提取出某日访问百度次数最多的那个IP。
IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
3.bit-map
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展:bloom filter可以看做是对bit-map的扩展
问题实例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map。
4.堆
适用范围:海量数据前n大,并且n比较小,堆可以放入内存
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当前元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较小的情况,这样可以扫描一遍即可得到所有的前n元素,效率很高。
扩展:双堆,一个最大堆与一个最小堆结合,可以用来维护中位数。
问题实例:
1)100w个数中找最大的前100个数。
用一个100个元素大小的最小堆即可。
5.双层桶划分 —-其实本质上就是【分而治之】的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
6.数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
扩展:
问题实例:
7.倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = “it is what it is”
T1 = “what is it”
T2 = “it is a banana”
我们就能得到下面的反向文件索引:
“a”: {2}
“banana”: {2}
“is”: {0, 1, 2}
“it”: {0, 1, 2}
“what”: {0, 1}
检索的条件”what”, “is” 和 “it” 将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
8.外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择 败者树原理,最优归并树
扩展:
问题实例:
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
9.trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
1).有10个文件,每个文件1G, 每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序 。
2).1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
3).寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
10.分布式处理 mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
扩展:
问题实例:
1).The canonical example application of MapReduce is a process to count the appearances of
each different word in a set of documents:
void map(String name, String document):
// name: document name
// document: document contents
for each word w in document:
EmitIntermediate(w, 1);
void reduce(String word, Iterator partialCounts):
// key: a word
// values: a list of aggregated partial counts
int result = 0;
for each v in partialCounts:
result += ParseInt(v);
Emit(result);
Here, each document is split in words, and each word is counted initially with a “1” value by
the Map function, using the word as the result key. The framework puts together all the pairs
with the same key and feeds them to the same call to Reduce, thus this function just needs to
sum all of its input values to find the total appearances of that word.
2).海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
3).一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数的中数(median)?
经典问题分析
上千万or亿数据(有重复),统计其中出现次数最多的前N个数据,分两种情况:可一次读入内存,不可一次读入。
可用思路:trie树+堆,数据库索引,划分子集分别统计,hash,分布式计算,近似统计,外排序
所谓的是否能一次读入内存,实际上应该指去除重复后的数据量。如果去重后数据可以放入内存,我们可以为数据建立字典,比如通过 map,hashmap,trie,然后直接进行统计即可。当然在更新每条数据的出现次数的时候,我们可以利用一个堆来维护出现次数最多的前N个数据,当然这样导致维护次数增加,不如完全统计后在求前N大效率高。
如果数据无法放入内存。一方面我们可以考虑上面的字典方法能否被改进以适应这种情形,可以做的改变就是将字典存放到硬盘上,而不是内存,这可以参考数据库的存储方法。
当然还有更好的方法,就是可以采用分布式计算,基本上就是map-reduce过程,首先可以根据数据值或者把数据hash(md5)后的值,将数据按照范围划分到不同的机子,最好可以让数据划分后可以一次读入内存,这样不同的机子负责处理各种的数值范围,实际上就是map。得到结果后,各个机子只需拿出各自的出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数据,这实际上就是reduce过程。
实际上可能想直接将数据均分到不同的机子上进行处理,这样是无法得到正确的解的。因为一个数据可能被均分到不同的机子上,而另一个则可能完全聚集到一个机子上,同时还可能存在具有相同数目的数据。比如我们要找出现次数最多的前100个,我们将1000万的数据分布到10台机器上,找到每台出现次数最多的前 100个,归并之后这样不能保证找到真正的第100个,因为比如出现次数最多的第100个可能有1万个,但是它被分到了10台机子,这样在每台上只有1千个,假设这些机子排名在1000个之前的那些都是单独分布在一台机子上的,比如有1001个,这样本来具有1万个的这个就会被淘汰,即使我们让每台机子选出出现次数最多的1000个再归并,仍然会出错,因为可能存在大量个数为1001个的发生聚集。因此不能将数据随便均分到不同机子上,而是要根据hash 后的值将它们映射到不同的机子上处理,让不同的机器处理一个数值范围。
而外排序的方法会消耗大量的IO,效率不会很高。而上面的分布式方法,也可以用于单机版本,也就是将总的数据根据值的范围,划分成多个不同的子文件,然后逐个处理。处理完毕之后再对这些单词的及其出现频率进行一个归并。实际上就可以利用一个外排序的归并过程。
另外还可以考虑近似计算,也就是我们可以通过结合自然语言属性,只将那些真正实际中出现最多的那些词作为一个字典,使得这个规模可以放入内存。