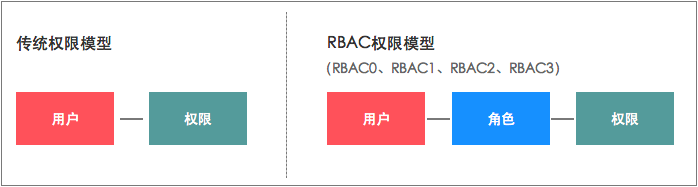
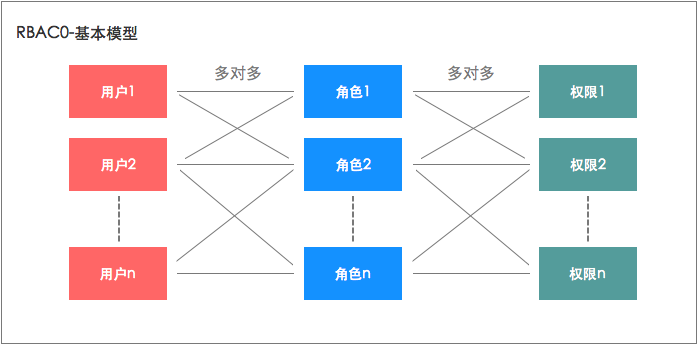
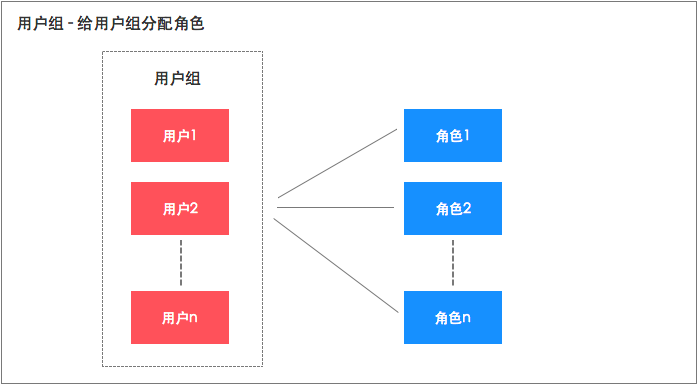
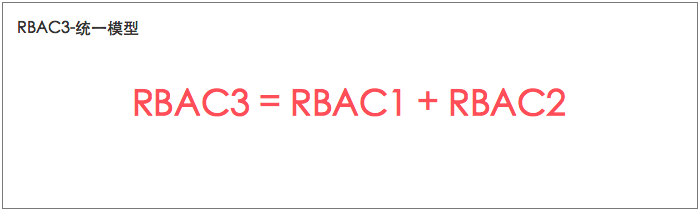RBAC不用给用户单个分配权限,只用指向对应的角色就会有对应的权限,而且分配权限和收回权限都很方便

5个关系对应5张表



五张表设计

1 CREATE TABLE `user` ( 2 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 3 `name` varchar(20) NOT NULL DEFAULT '' COMMENT '姓名', 4 `email` varchar(30) NOT NULL DEFAULT '' COMMENT '邮箱', 5 `is_admin` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否是超级管理员 1表示是 0 表示不是', 6 `status` tinyint(1) NOT NULL DEFAULT '1' COMMENT '状态 1:有效 0:无效', 7 `updated_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '最后一次更新时间', 8 `created_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '插入时间', 9 PRIMARY KEY (`id`), 10 KEY `idx_email` (`email`) 11 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表'; 12 13 CREATE TABLE `role` ( 14 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 15 `name` varchar(50) NOT NULL DEFAULT '' COMMENT '角色名称', 16 `status` tinyint(1) NOT NULL DEFAULT '1' COMMENT '状态 1:有效 0:无效', 17 `updated_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '最后一次更新时间', 18 `created_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '插入时间', 19 PRIMARY KEY (`id`) 20 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='角色表'; 21 22 CREATE TABLE `user_role` ( 23 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 24 `uid` int(11) NOT NULL DEFAULT '0' COMMENT '用户id', 25 `role_id` int(11) NOT NULL DEFAULT '0' COMMENT '角色ID', 26 `created_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '插入时间', 27 PRIMARY KEY (`id`), 28 KEY `idx_uid` (`uid`) 29 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户角色表'; 30 31 CREATE TABLE `access` ( 32 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 33 `title` varchar(50) NOT NULL DEFAULT '' COMMENT '权限名称', 34 `urls` varchar(1000) NOT NULL DEFAULT '' COMMENT 'json 数组', 35 `status` tinyint(1) NOT NULL DEFAULT '1' COMMENT '状态 1:有效 0:无效', 36 `updated_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '最后一次更新时间', 37 `created_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '插入时间', 38 PRIMARY KEY (`id`) 39 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='权限详情表'; 40 41 CREATE TABLE `role_access` ( 42 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 43 `role_id` int(11) NOT NULL DEFAULT '0' COMMENT '角色id', 44 `access_id` int(11) NOT NULL DEFAULT '0' COMMENT '权限id', 45 `created_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '插入时间', 46 PRIMARY KEY (`id`), 47 KEY `idx_role_id` (`role_id`) 48 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='角色权限表'; 49 50 CREATE TABLE `app_access_log` ( 51 `id` int(11) NOT NULL AUTO_INCREMENT, 52 `uid` bigint(20) NOT NULL DEFAULT '0' COMMENT '品牌UID', 53 `target_url` varchar(255) NOT NULL DEFAULT '' COMMENT '访问的url', 54 `query_params` longtext NOT NULL COMMENT 'get和post参数', 55 `ua` varchar(255) NOT NULL DEFAULT '' COMMENT '访问ua', 56 `ip` varchar(32) NOT NULL DEFAULT '' COMMENT '访问ip', 57 `note` varchar(1000) NOT NULL DEFAULT '' COMMENT 'json格式备注字段', 58 `created_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, 59 PRIMARY KEY (`id`), 60 KEY `idx_uid` (`uid`) 61 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户操作记录表'; 62 63 64 INSERT INTO `user` (`id`, `name`, `email`, `is_admin`, `status`, `updated_time`, `created_time`) 65 VALUES(1, '超级管理员', 'apanly@163.com', 1, 1, '2016-11-15 13:36:30', '2016-11-15 13:36:30');
用户与角色关联起来,角色与权限关联起来,通过判断角色来管理权限(哪些页面不能访问)


判断权限逻辑:根据用户ID取出用户角色==》如果是超级管理员则不需要做权限判断,否则根据角色取出所属权限==》根据权限取出可访问链接列表==》判断当前操作是否在列表中==》无权限则返回提示页面;


本内容整理自慕课网视频教程——《RBAC打造通用web管理权限》